项目下载:https://share.feijipan.com/s/3Ubdme4i
一、系统架构
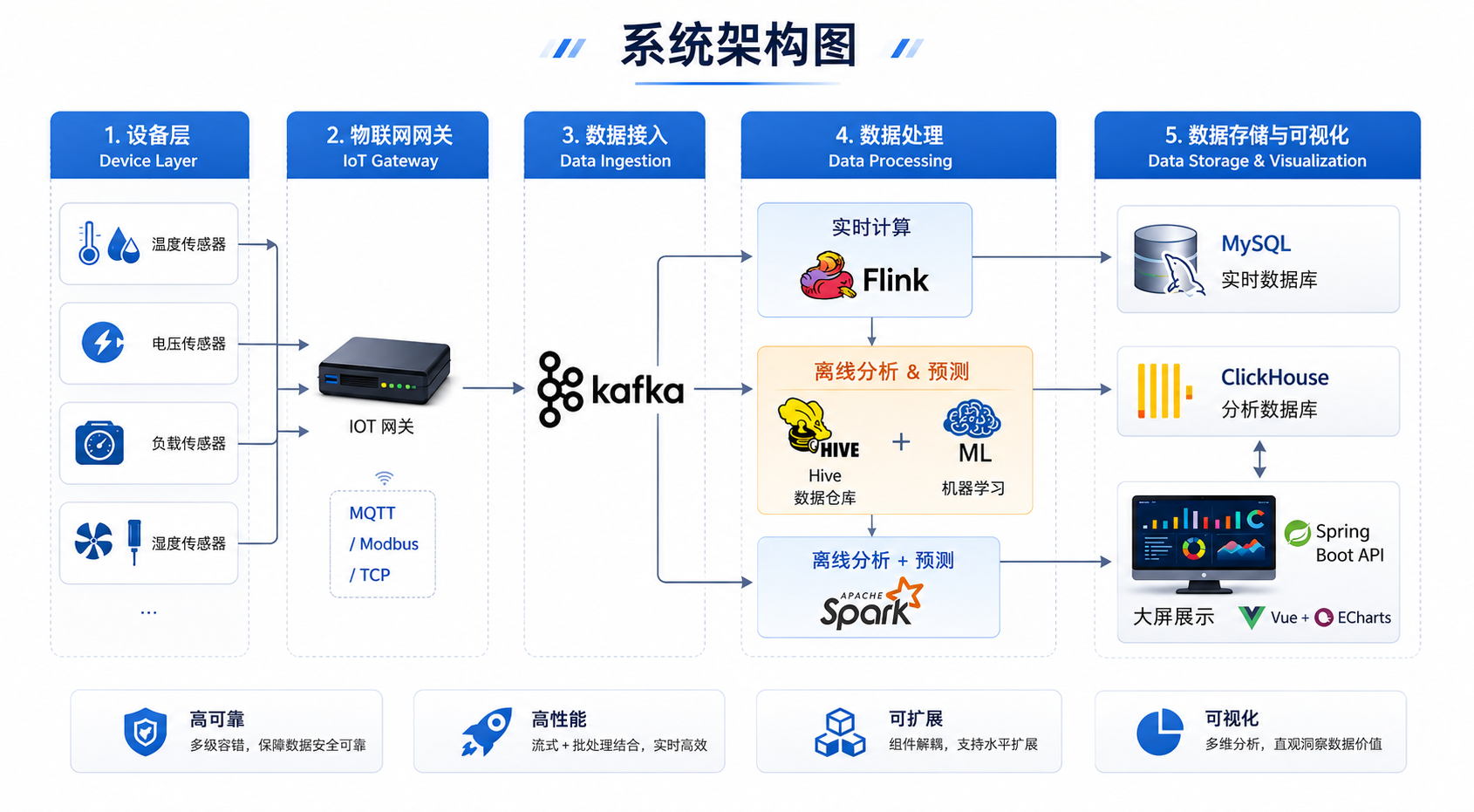

二、环境准备(首次搭建必读)
详见《实训项目准备清单》,主要包括:
镜像配置(Flink 1.15.4 / MySQL / ZooKeeper / SELinux)
数据库建表(MySQL / Hive / ClickHouse)
Kafka Topic 创建
历史数据上传到 /opt/datas/
JAR 包和脚本上传到 /opt/jars/
三、启动顺序总览
| 步骤 | 服务 | 节点 |
|---|---|---|
| 第 1 步 | Hadoop(HDFS + YARN) | master / slave1 |
| 第 2 步 | ZooKeeper | master / slave1 / slave2 |
| 第 3 步 | Kafka | master / slave1 / slave2 |
| 第 4 步 | Hive Metastore | master |
| 第 5 步 | Flink 集群 | master |
| 第 6 步 | 设备数据模拟采集 | master |
| 第 7 步 | 实时分析作业 | master |
| 第 8 步 | 离线分析作业 | master |
| 第 9 步 | Spark ML 预测作业 | master |
| 第 10 步 | Spring Boot 后端 | master |
| 第 11 步 | Vue 前端 | 本地 / master |
✅ 第 1 步:启动 Hadoop集群
# master 节点:启动 HDFS
start-dfs.sh
# slave1 节点:启动 YARN
start-yarn.sh
若 HDFS 处于安全模式,执行以下命令退出:
hdfs dfsadmin -safemode get
hdfs dfsadmin -safemode leave
✅ 第 2 步:启动 ZooKeeper
在 master、slave1、slave2 上分别执行:
# 启动
zkServer.sh start
# 查看角色(应出现 leader / follower)
zkServer.sh status
✅ 第 3 步:启动 Kafka
在 master、slave1、slave2 上分别执行:
kafka-server-start.sh -daemon /opt/apps/kafka/config/server.properties
✅ 第 4 步:启动 Hive Metastore
# master 节点执行
nohup hive --service metastore &
Hive Metastore 默认监听端口 9083,Flink / Spark 连接 Hive 时依赖此服务。
✅ 第 5 步:启动 Flink 集群
# # master 节点执行
start-cluster.sh
✅ 第 6 步:启动 数据采集脚本
# 在 master 节点执行: cd /opt/datas # 执行 Python 程序持续产生模拟数据并写入 Kafka python 01_device_status_sim.py | \ kafka-console-producer.sh \ --broker-list master:9092 \ --topic device_status_topic
验证数据是否写入 Kafka(在slave1验证):
kafka-console-consumer.sh \ --bootstrap-server master:9092 \ --topic device_status_topic \ --from-beginning
✅ 第 7 步:提交 Flink 实时分析作业
功能:统计在线设备数、告警数量、温度趋势、告警设备排名
方法 1:开发调试模式(IDEA 本地运行)
打开项目 flink-rt-metrics,运行启动类:
RtMetricsSqlJob
方法 2:集群部署模式
flink run -c com.demo.flink.RtMetricsSqlJob \ /opt/jars/flink-rt-metrics-1.0.0.jar \ --jobmanager.memory.process.size 512m \ --taskmanager.memory.process.size 512m \ --taskmanager.numberOfTaskSlots 1 \ --parallelism 1
方法 3:YARN Per-Job 模式
flink run -t yarn-per-job \ -c com.demo.flink.RtMetricsSqlJob \ /opt/jars/flink-rt-metrics-1.0.0.jar
验证:查询 MySQL 是否有数据写入:
SELECT * FROM rt.rt_kpi_online_10s ORDER BY ts DESC LIMIT 5;
✅ 第 8 步:完成 离线分析作业
8.1 历史数据入湖
功能:将
/opt/datas/目录下的历史 CSV 数据导入 Hive ODS 分区表iot.ods_device_status_di,为后续历史趋势分析与机器学习训练提供数据底座。
方法 1:开发调试模式(Hive 客户端运行)
进入 Hive 客户端,依次执行:
-- 1. 将 CSV 数据加载到临时表 LOAD DATA LOCAL INPATH '/opt/datas/device_status_2026_01.csv' INTO TABLE iot.ods_device_status_csv_tmp; -- 2. 开启动态分区 SET hive.exec.dynamic.partition=true; SET hive.exec.dynamic.partition.mode=nonstrict; -- 3. 从临时表写入 ODS 分区表(清洗 + 生成 ts / dt 字段) INSERT OVERWRITE TABLE iot.ods_device_status_di PARTITION (dt) SELECT event_type, device_id, status, temperature, `load`, voltage, event_time, from_unixtime(unix_timestamp(event_time, 'yyyy-MM-dd HH:mm:ss')) AS ts, substr(event_time, 1, 10) AS dt FROM iot.ods_device_status_csv_tmp WHERE event_type <> 'event_type';
验证: 查看 Hive ODS 表是否已生成分区数据:
SHOW PARTITIONS iot.ods_device_status_di; SELECT COUNT(*) FROM iot.ods_device_status_di;
8.2 实时数据入湖
功能:通过 Spark Structured Streaming 从 Kafka 持续消费设备数据,每 10 秒写入一批到 Hive ODS 分区表
iot.ods_device_status_di,按日期自动分区。
方法 1:开发调试模式(IDEA 本地运行)
打开项目 spark-ods-ingest,运行启动类:
KafkaToHiveDeviceStatusJob
方法 2:本地模式(调试用)
spark-submit \ --class com.demo.spark.KafkaToHiveDeviceStatusJob \ --master local[1] \ /opt/jars/spark-job-1.0.0.jar
方法 3:YARN Client 模式
spark-submit \ --class com.demo.spark.KafkaToHiveDeviceStatusJob \ --master yarn \ --deploy-mode client \ /opt/jars/spark-job-1.0.0.jar
验证: 查询 Hive ODS 表是否有当天最新数据:
-- 查看当天分区(最后一行应为今日日期) SHOW PARTITIONS iot.ods_device_status_di; -- 查看当天最新写入的 5 条数据 SELECT * FROM iot.ods_device_status_di WHERE dt = '2026-05-27' ORDER BY ts DESC LIMIT 5;
⚠️ 实时数据入湖为常驻运行作业,启动后持续消费 Kafka 数据,Structured Streaming 会按日期自动写入对应分区(今天写
dt=今天,跨天后自动切换写dt=明天),无需人工干预。运行前请确保 Python 模拟脚本已持续写入 Kafka。
8.3 离线数据分析(历史 7 天温度趋势)
功能:基于 Hive ODS 表中的历史明细数据,按天聚合计算每日平均温度与最高温度,结果写入 ClickHouse 的
dws_temp_trend_day表,供大屏"历史 7 天温度趋势"图表使用。
方法 1:开发调试模式(IDEA 本地运行)
打开项目 spark-ods-ingest,运行启动类:
TempTrendBatchJob
方法 2:本地模式(调试用)
spark-submit \ --class com.demo.spark.TempTrendBatchJob \ --master local[1] \ /opt/jars/spark-job-1.0.0.jar
方法 3:YARN Client 模式
spark-submit \ --class com.demo.spark.TempTrendBatchJob \ --master yarn \ --deploy-mode client \ /opt/jars/spark-job-1.0.0.jar
验证: 查询 ClickHouse 是否有历史趋势数据:
# 进入 ClickHouse 多行模式 clickhouse-client -m
-- 查看历史温度趋势数据(按日期升序) SELECT * FROM iot_report.dws_temp_trend_day ORDER BY dt; -- 查看近 7 天数据 SELECT * FROM iot_report.dws_temp_trend_day ORDER BY dt DESC LIMIT 7;
⚠️ 该作业为一次性批量任务,每次运行会先清空 ClickHouse 目标表再全量写入。生产环境通过 DolphinScheduler / Azkaban 等调度工具每天凌晨定时触发,本项目教学环境中手动运行即可。
✅ 第 9 步:启动 Spark ML 预测作业
9.1 上传训练数据
# 在HDFS上创建数据目录 hdfs dfs -mkdir /datas # 把master上的历史数据上传到HDFS上 hdfs dfs -put /opt/datas/device_status_with_label_2026_01.csv /datas/
9.2 模型训练作业
功能:使用历史数据(带标签)训练随机森林分类模型,并将训练好的模型保存到 HDFS,供后续实时预测加载使用。
方法 1:开发调试模式(IDEA 本地运行)
打开项目 spark-ods-ingest,运行启动类:
DeviceTrainModelJob
方法 2:本地模式(调试用)
spark-submit \ --class com.demo.spark.DeviceAbnormalPredictJob \ --master local[1] \ /opt/jars/spark-job-1.0.0.jar
方法 3:YARN Client 模式
spark-submit \ --class com.demo.spark.DeviceAbnormalPredictJob \ --master yarn \ --deploy-mode client \ /opt/jars/spark-job-1.0.0.jar
⚠️ 训练作业为一次性任务,模型训练完成后即退出。模型只需训练一次,后续实时预测会自动加载该模型,无需每次重新训练。
9.3 实时预测作业
功能:对设备状态进行实时预测,结果写入 ClickHouse
方法 1:开发调试模式(IDEA 本地运行)
打开项目 spark-ods-ingest,运行启动类:
DevicePredictStreamJob
方法 2:本地模式(调试用)
spark-submit \ --class com.demo.spark.DevicePredictStreamJob \ --master local[1] \ /opt/jars/spark-job-1.0.0.jar
方法 3:YARN Client 模式
spark-submit \ --class com.demo.spark.DevicePredictStreamJob \ --master yarn \ --deploy-mode client \ /opt/jars/spark-job-1.0.0.jar
验证:查询 ClickHouse 是否有预测数据:
# 进入 ClickHouse 多行模式 clickhouse-client -m
SELECT * FROM iot_report.dws_device_pred_detail ORDER BY created_at DESC LIMIT 5;
✅ 第 10 步:启动 Spring Boot 后端服务
方法 1:开发调试模式(IDEA 本地运行)
打开项目 smart-screen-backend,运行启动类:
SmartScreenBackendApplication
方法 2:集群部署模式
# master 节点,新开终端执行 java -jar /opt/jars/smart-screen-backend-1.0.0-SNAPSHOT.jar
接口验证:
| 接口 | 地址 |
|---|---|
| KPI 汇总接口 | http://localhost:8080/api/kpi/summary |
| 温度趋势 | http://localhost:8080/api/kpi/tempTrend?limit=60 |
| 告警 Top | http://localhost:8080/api/kpi/alarmTop?limit=3 |
| 历史 7 天温度 | http://localhost:8080/api/history/temp7d |
| 风险环形图 | http://localhost:8080/api/predict/riskPie |
| 高风险 Top3 | http://localhost:8080/api/predict/topRisk?limit=3 |
✅ 第 11 步:启动 Vue 前端
方法 1:本地开发模式(Vite)
# 在IDEA的 smart-screen-frontend 项目根目录执行 npm run dev
浏览器访问:http://localhost:5173
方法 2:服务器部署模式(Nginx)
前提:Spring Boot 后端必须在集群中运行
浏览器访问:http://192.168.36.100
四、一键运行项目
准备工作: 将以下文件统一放置到
master节点的/opt/jars/目录下:
文件 说明 flink-rt-metrics-1.0.0.jarFlink 实时计算作业 spark-job-1.0.0.jarSpark 离线分析 + ML 预测作业 smart-screen-backend-1.0.0-SNAPSHOT.jarSpring Boot 后端服务 start-all.sh一键启动脚本 stop-all.sh一键停止脚本 运行方式:
## 首次运行(需要先赋予执行权限): # 赋予启动脚本执行权限 chmod +x /opt/jars/start-all.sh # 赋予关闭脚本执行权限 chmod +x /opt/jars/stop-all.sh## 后续运行(权限已设置,直接执行): # 一键启动项目 /opt/jars/start-all.sh # 一键关闭项目 /opt/jars/stop-all.sh
1.一键启动项目脚本
#!/bin/bash
# =============================================================
# 《智慧设备运行预测大屏》一键启动脚本
# 运行节点:master
# 使用方式:chmod +x start-all.sh && ./start-all.sh
# 重复执行安全:已运行的服务自动跳过
#
# 启动顺序:
# 1. Hadoop(HDFS + YARN)
# 2. ZooKeeper
# 3. Kafka
# 4. Hive Metastore
# 5. Flink 集群 + 实时分析作业
# 6. 设备数据模拟采集
# 7. 离线分析作业(询问执行)
# └─ 7.1 历史数据入湖(可选)
# └─ 7.2 实时数据入湖(必执行)
# └─ 7.3 离线温度趋势分析(可选,等 7.2 产生数据后执行)
# 8. Spark ML 预测作业(询问执行)
# └─ 8.1 上传训练数据(可选)
# └─ 8.2 模型训练(可选)
# └─ 8.3 实时预测(必执行)
# 9. Spring Boot 后端
# =============================================================
# ---------- 颜色定义 ----------
RED='\033[0;31m'
GREEN='\033[0;32m'
YELLOW='\033[1;33m'
BLUE='\033[0;34m'
CYAN='\033[0;36m'
MAGENTA='\033[0;35m'
NC='\033[0m'
# ---------- 工具函数 ----------
log_step() { echo ""; echo -e "${BLUE}========================================${NC}"; echo -e "${CYAN} $1${NC}"; echo -e "${BLUE}========================================${NC}"; }
log_sub() { echo -e "${MAGENTA} ▸ $1${NC}"; }
log_info() { echo -e "${YELLOW}[INFO]${NC} $1"; }
log_ok() { echo -e "${GREEN}[OK]${NC} $1"; }
log_skip() { echo -e "${CYAN}[SKIP]${NC} $1"; }
log_error() { echo -e "${RED}[ERROR]${NC} $1"; }
log_fatal() { echo -e "${RED}[FATAL]${NC} $1"; exit 1; }
wait_sec() { log_info "等待 $1 秒..."; sleep "$1"; }
# 询问 Y/N,默认 N(直接回车 = 不执行)
ask_yes_no() {
local question="$1"
local answer
echo ""
read -p "$(echo -e ${YELLOW}[ASK]${NC} $question [y/N]: )" answer
[ "$answer" = "y" ] || [ "$answer" = "Y" ]
}
# 检查本地 Java 进程
is_running_local() {
source /etc/profile && jps 2>/dev/null | grep -qw "$1" 2>/dev/null \
|| pgrep -f "$1" > /dev/null 2>&1
}
# 检查远程节点 Java 进程
is_running_remote() {
local result
result=$(ssh "$1" "source /etc/profile && jps 2>/dev/null | grep -w '$2'" 2>/dev/null)
[ -n "$result" ]
}
# 检查本地端口是否占用
port_in_use() { ss -tlnp 2>/dev/null | grep -q ":$1 "; }
# 等待今天的 Hive 分区出现并有数据(最多等 2 分钟)
# 用于确保 7.2 实时入湖已经处理了 Kafka 中积压的数据
wait_for_today_partition() {
local today=$(date +%Y-%m-%d)
local hdfs_path="/user/hive/warehouse/iot.db/ods_device_status_di/dt=$today"
local max_wait=24 # 24 次 x 5 秒 = 2 分钟
local i
log_info "等待 7.2 实时入湖把今天($today)的数据写入 Hive..."
for i in $(seq 1 $max_wait); do
# 检查今天的分区目录是否存在
if hdfs dfs -test -e "$hdfs_path" 2>/dev/null; then
# 检查分区内是否有文件
local file_count=$(hdfs dfs -ls "$hdfs_path" 2>/dev/null | grep -c "^-")
if [ "$file_count" -gt 0 ]; then
log_ok "检测到今天的数据已写入 Hive(共 $file_count 个文件)"
return 0
fi
fi
log_info " 等待中... ($((i*5))/$((max_wait*5)) 秒)"
sleep 5
done
log_error "等待超时,7.2 可能未正常运行;7.3 将基于现有数据执行"
return 1
}
# ---------- 配置 ----------
SSH_ENV="source /etc/profile && "
SLAVE1="slave1"
SLAVE2="slave2"
KAFKA_CONFIG="/opt/apps/kafka/config/server.properties"
DATA_DIR="/opt/datas"
SIM_SCRIPT="01_device_status_sim.py"
HISTORY_CSV="device_status_2026_01.csv"
TRAIN_CSV="device_status_with_label_2026_01.csv"
HDFS_TRAIN_DIR="/datas"
KAFKA_TOPIC="device_status_topic"
KAFKA_BROKER="master:9092"
FLINK_JAR="/opt/jars/flink-rt-metrics-1.0.0.jar"
FLINK_CLASS="com.demo.flink.RtMetricsSqlJob"
SPARK_JAR="/opt/jars/spark-job-1.0.0.jar"
SPARK_INGEST_CLASS="com.demo.spark.KafkaToHiveDeviceStatusJob"
SPARK_TREND_CLASS="com.demo.spark.TempTrendBatchJob"
SPARK_TRAIN_CLASS="com.demo.spark.DeviceTrainModelJob"
SPARK_PREDICT_CLASS="com.demo.spark.DevicePredictStreamJob"
BACKEND_JAR="/opt/jars/smart-screen-backend-1.0.0-SNAPSHOT.jar"
PID_FILE="/tmp/bigdata-pids.env"
> "$PID_FILE"
# =============================================================
# 第 1 步:启动 Hadoop 集群(HDFS + YARN)
# =============================================================
log_step "第 1 步:启动 Hadoop 集群(HDFS + YARN)"
if is_running_local "NameNode"; then
log_skip "HDFS NameNode(已在运行)"
else
log_info "启动 HDFS..."
source /etc/profile && start-dfs.sh \
&& log_ok "HDFS 启动成功" \
|| log_error "HDFS 启动失败"
fi
if is_running_remote "$SLAVE1" "ResourceManager"; then
log_skip "YARN ResourceManager(已在运行)"
else
log_info "在 slave1 启动 YARN..."
ssh "$SLAVE1" "${SSH_ENV}start-yarn.sh" \
&& log_ok "YARN 启动成功" \
|| log_error "YARN 启动失败"
fi
wait_sec 5
# =============================================================
# 第 2 步:启动 ZooKeeper(3 个节点)
# =============================================================
log_step "第 2 步:启动 ZooKeeper(master / slave1 / slave2)"
for NODE in master "$SLAVE1" "$SLAVE2"; do
if [ "$NODE" = "master" ]; then
STATUS=$(source /etc/profile && zkServer.sh status 2>&1)
else
STATUS=$(ssh "$NODE" "${SSH_ENV}zkServer.sh status 2>&1")
fi
if echo "$STATUS" | grep -q "Mode:"; then
log_skip "[$NODE] ZooKeeper(已在运行)"
else
log_info "[$NODE] 启动 ZooKeeper..."
if [ "$NODE" = "master" ]; then
source /etc/profile && zkServer.sh start \
&& log_ok "[$NODE] ZooKeeper 启动完成" \
|| log_error "[$NODE] ZooKeeper 启动失败"
else
ssh "$NODE" "${SSH_ENV}zkServer.sh start" \
&& log_ok "[$NODE] ZooKeeper 启动完成" \
|| log_error "[$NODE] ZooKeeper 启动失败"
fi
fi
done
wait_sec 3
# =============================================================
# 第 3 步:启动 Kafka(3 个节点)
# =============================================================
log_step "第 3 步:启动 Kafka(master / slave1 / slave2)"
for NODE in master "$SLAVE1" "$SLAVE2"; do
if [ "$NODE" = "master" ]; then
if [ -n "$(source /etc/profile && jps 2>/dev/null | grep -w Kafka)" ]; then
log_skip "[$NODE] Kafka(已在运行)"
else
log_info "[$NODE] 启动 Kafka..."
source /etc/profile && kafka-server-start.sh -daemon "$KAFKA_CONFIG" \
&& log_ok "[$NODE] Kafka 启动完成" \
|| log_error "[$NODE] Kafka 启动失败"
fi
else
if [ -n "$(ssh "$NODE" "source /etc/profile && jps 2>/dev/null | grep -w Kafka")" ]; then
log_skip "[$NODE] Kafka(已在运行)"
else
log_info "[$NODE] 启动 Kafka..."
ssh "$NODE" "${SSH_ENV}kafka-server-start.sh -daemon $KAFKA_CONFIG" \
&& log_ok "[$NODE] Kafka 启动完成" \
|| log_error "[$NODE] Kafka 启动失败"
fi
fi
done
wait_sec 8
# =============================================================
# 第 4 步:启动 Hive Metastore
# =============================================================
log_step "第 4 步:启动 Hive Metastore"
if port_in_use 9083; then
log_skip "Hive Metastore(端口 9083 已占用)"
else
log_info "后台启动 Hive Metastore..."
nohup hive --service metastore > /tmp/hive-metastore.log 2>&1 &
HIVE_PID=$!
echo "HIVE_PID=$HIVE_PID" >> "$PID_FILE"
log_ok "Hive Metastore 已后台启动,PID=$HIVE_PID"
fi
wait_sec 10
# =============================================================
# 第 5 步:启动 Flink 集群 + 提交实时分析作业
# =============================================================
log_step "第 5 步:启动 Flink 集群 + 实时分析作业"
if port_in_use 8081; then
log_skip "Flink 集群(端口 8081 已占用)"
else
log_info "启动 Flink 集群..."
source /etc/profile && start-cluster.sh \
&& log_ok "Flink 集群启动成功" \
|| log_error "Flink 集群启动失败"
fi
wait_sec 5
if [ ! -f "$FLINK_JAR" ]; then
log_error "Flink JAR 不存在:$FLINK_JAR,跳过作业提交"
else
RUNNING_COUNT=$(curl -s http://localhost:8081/jobs/overview 2>/dev/null \
| grep -o '"state":"RUNNING"' | wc -l)
if [ "$RUNNING_COUNT" -gt 0 ]; then
log_skip "Flink 作业(已有 $RUNNING_COUNT 个作业在运行)"
else
log_info "提交 Flink 作业..."
source /etc/profile && flink run -c "$FLINK_CLASS" "$FLINK_JAR" \
--jobmanager.memory.process.size 512m \
--taskmanager.memory.process.size 512m \
--taskmanager.numberOfTaskSlots 1 \
--parallelism 1 \
&& log_ok "Flink 作业提交成功" \
|| log_error "Flink 作业提交失败"
fi
fi
wait_sec 3
# =============================================================
# 第 6 步:启动设备数据模拟采集(Python -> Kafka)
# =============================================================
log_step "第 6 步:启动设备数据模拟采集"
if is_running_local "$SIM_SCRIPT"; then
log_skip "数据采集(已在运行)"
else
if [ ! -f "$DATA_DIR/$SIM_SCRIPT" ]; then
log_error "模拟脚本不存在:$DATA_DIR/$SIM_SCRIPT"
else
log_info "后台启动 Python 模拟 -> Kafka 管道..."
nohup bash -c "cd $DATA_DIR && python $SIM_SCRIPT | \
kafka-console-producer.sh \
--broker-list $KAFKA_BROKER \
--topic $KAFKA_TOPIC" \
> /tmp/kafka-producer.log 2>&1 &
PRODUCER_PID=$!
echo "PRODUCER_PID=$PRODUCER_PID" >> "$PID_FILE"
log_ok "数据采集已后台启动,PID=$PRODUCER_PID"
fi
fi
wait_sec 3
# =============================================================
# 第 7 步:完成离线分析作业
# =============================================================
log_step "第 7 步:完成离线分析作业"
# 标记本轮是否启动了 7.2(用于决定 7.3 之前是否需要等待)
INGEST_JUST_STARTED=0
if ask_yes_no "是否进行离线数据分析?(包含历史数据入湖 + 离线温度趋势分析)"; then
# ---------- 7.1 历史数据入湖 ----------
log_sub "7.1 历史数据入湖"
# 检查 CSV 文件是否存在
if [ ! -f "$DATA_DIR/$HISTORY_CSV" ]; then
log_fatal "历史数据文件不存在:$DATA_DIR/$HISTORY_CSV,请先上传后重试"
fi
# 检查 Hive 表是否已有数据
HIVE_COUNT=$(hive -e "SELECT COUNT(*) FROM iot.ods_device_status_di;" 2>/dev/null | tail -1)
if [ -n "$HIVE_COUNT" ] && [ "$HIVE_COUNT" -gt 0 ] 2>/dev/null; then
log_skip "历史数据已入湖(共 $HIVE_COUNT 条),跳过 7.1"
else
log_info "执行历史数据入湖(CSV -> Hive ODS)..."
hive -e "
LOAD DATA LOCAL INPATH '$DATA_DIR/$HISTORY_CSV'
INTO TABLE iot.ods_device_status_csv_tmp;
SET hive.exec.dynamic.partition=true;
SET hive.exec.dynamic.partition.mode=nonstrict;
INSERT OVERWRITE TABLE iot.ods_device_status_di PARTITION (dt)
SELECT
event_type, device_id, status, temperature, \`load\`, voltage, event_time,
from_unixtime(unix_timestamp(event_time, 'yyyy-MM-dd HH:mm:ss')) AS ts,
substr(event_time, 1, 10) AS dt
FROM iot.ods_device_status_csv_tmp
WHERE event_type <> 'event_type';
" > /tmp/hive-load.log 2>&1 \
&& log_ok "7.1 历史数据入湖完成" \
|| log_error "7.1 历史数据入湖失败,日志:/tmp/hive-load.log"
fi
# ---------- 7.2 实时数据入湖(必执行)----------
log_sub "7.2 实时数据入湖"
if is_running_local "KafkaToHiveDeviceStatusJob"; then
log_skip "实时数据入湖(已在运行)"
elif [ ! -f "$SPARK_JAR" ]; then
log_error "Spark JAR 不存在:$SPARK_JAR,跳过 7.2"
else
log_info "后台启动 Spark 实时入湖作业..."
nohup spark-submit \
--class "$SPARK_INGEST_CLASS" \
--master local[1] \
"$SPARK_JAR" \
> /tmp/spark-ingest.log 2>&1 &
INGEST_PID=$!
echo "INGEST_PID=$INGEST_PID" >> "$PID_FILE"
log_ok "7.2 实时入湖作业已后台启动,PID=$INGEST_PID"
INGEST_JUST_STARTED=1
fi
# ---------- 7.3 离线温度趋势分析 ----------
# 关键:如果本轮刚启动了 7.2,必须等它把今天的数据写入 Hive 后再跑 7.3,
# 否则 7.3 读不到今天的最新分区,ClickHouse 会缺少最新数据。
log_sub "7.3 离线温度趋势分析"
if [ "$INGEST_JUST_STARTED" = "1" ]; then
wait_for_today_partition
else
log_info "7.2 已在运行中,跳过等待,直接执行 7.3"
fi
if [ ! -f "$SPARK_JAR" ]; then
log_error "Spark JAR 不存在:$SPARK_JAR,跳过 7.3"
else
log_info "执行离线温度趋势分析(Hive -> ClickHouse)..."
spark-submit \
--class "$SPARK_TREND_CLASS" \
--master local[4] \
--driver-memory 2g \
--conf spark.sql.shuffle.partitions=4 \
--conf spark.ui.enabled=false \
"$SPARK_JAR" \
> /tmp/spark-trend.log 2>&1 \
&& log_ok "7.3 离线温度趋势分析完成" \
|| log_error "7.3 离线温度趋势分析失败,日志:/tmp/spark-trend.log"
fi
else
# ---------- 未选择离线分析,但仍需启动实时入湖(常驻服务)----------
log_info "跳过离线分析(7.1、7.3),仅启动实时入湖(7.2)"
log_sub "7.2 实时数据入湖"
if is_running_local "KafkaToHiveDeviceStatusJob"; then
log_skip "实时数据入湖(已在运行)"
elif [ ! -f "$SPARK_JAR" ]; then
log_error "Spark JAR 不存在:$SPARK_JAR,跳过 7.2"
else
log_info "后台启动 Spark 实时入湖作业..."
nohup spark-submit \
--class "$SPARK_INGEST_CLASS" \
--master local[1] \
"$SPARK_JAR" \
> /tmp/spark-ingest.log 2>&1 &
INGEST_PID=$!
echo "INGEST_PID=$INGEST_PID" >> "$PID_FILE"
log_ok "7.2 实时入湖作业已后台启动,PID=$INGEST_PID"
fi
fi
wait_sec 3
# =============================================================
# 第 8 步:Spark ML 预测作业
# =============================================================
log_step "第 8 步:Spark ML 预测作业"
if ask_yes_no "是否进行模型训练?(包含上传训练数据 + 训练模型)"; then
# ---------- 8.1 上传训练数据 ----------
log_sub "8.1 上传训练数据到 HDFS"
# 检查本地训练数据是否存在
if [ ! -f "$DATA_DIR/$TRAIN_CSV" ]; then
log_fatal "训练数据文件不存在:$DATA_DIR/$TRAIN_CSV,请先上传后重试"
fi
# 检查 HDFS 上是否已存在
if hdfs dfs -test -e "$HDFS_TRAIN_DIR/$TRAIN_CSV" 2>/dev/null; then
log_skip "训练数据已存在于 HDFS:$HDFS_TRAIN_DIR/$TRAIN_CSV,跳过 8.1"
else
log_info "创建 HDFS 目录 $HDFS_TRAIN_DIR..."
hdfs dfs -mkdir -p "$HDFS_TRAIN_DIR" 2>/dev/null
log_info "上传训练数据到 HDFS..."
hdfs dfs -put "$DATA_DIR/$TRAIN_CSV" "$HDFS_TRAIN_DIR/" \
&& log_ok "8.1 训练数据上传成功" \
|| log_error "8.1 训练数据上传失败"
fi
# ---------- 8.2 模型训练 ----------
log_sub "8.2 模型训练"
if [ ! -f "$SPARK_JAR" ]; then
log_error "Spark JAR 不存在:$SPARK_JAR,跳过 8.2"
else
log_info "执行模型训练(DeviceTrainModelJob)..."
spark-submit \
--class "$SPARK_TRAIN_CLASS" \
--master local[1] \
"$SPARK_JAR" \
> /tmp/spark-train.log 2>&1 \
&& log_ok "8.2 模型训练完成" \
|| log_error "8.2 模型训练失败,日志:/tmp/spark-train.log"
fi
else
log_info "跳过模型训练(8.1、8.2),直接启动实时预测(8.3)"
fi
# ---------- 8.3 实时预测(必执行)----------
log_sub "8.3 实时预测"
if [ ! -f "$SPARK_JAR" ]; then
log_error "Spark JAR 不存在:$SPARK_JAR,跳过 8.3"
elif is_running_local "DevicePredictStreamJob"; then
log_skip "实时预测作业(已在运行)"
else
log_info "后台启动 Spark 实时预测作业..."
nohup spark-submit \
--class "$SPARK_PREDICT_CLASS" \
--master local[1] \
"$SPARK_JAR" \
> /tmp/spark-predict.log 2>&1 &
PREDICT_PID=$!
echo "PREDICT_PID=$PREDICT_PID" >> "$PID_FILE"
log_ok "8.3 实时预测作业已后台启动,PID=$PREDICT_PID"
fi
wait_sec 3
# =============================================================
# 第 9 步:启动 Spring Boot 后端
# =============================================================
log_step "第 9 步:启动 Spring Boot 后端"
if [ ! -f "$BACKEND_JAR" ]; then
log_error "后端 JAR 不存在:$BACKEND_JAR,跳过本步骤"
elif port_in_use 8080; then
log_skip "Spring Boot 后端(端口 8080 已占用)"
else
log_info "后台启动 Spring Boot..."
nohup java -jar "$BACKEND_JAR" \
> /tmp/backend.log 2>&1 &
BACKEND_PID=$!
echo "BACKEND_PID=$BACKEND_PID" >> "$PID_FILE"
log_ok "后端服务已后台启动,PID=$BACKEND_PID"
fi
# =============================================================
# 启动完成汇总
# =============================================================
echo ""
echo -e "${GREEN}============================================${NC}"
echo -e "${GREEN} ✅ 所有服务启动完毕!${NC}"
echo -e "${GREEN}============================================${NC}"
echo ""
echo -e " ${CYAN}后台进程 PID:${NC}"
cat "$PID_FILE" | while IFS='=' read -r NAME PID; do
echo -e " ${CYAN}${NAME}${NC} = $PID"
done
echo ""
echo -e " ${CYAN}日志文件:${NC}"
echo -e " Hive Metastore -> /tmp/hive-metastore.log"
echo -e " Kafka 数据采集 -> /tmp/kafka-producer.log"
echo -e " Spark 实时入湖 -> /tmp/spark-ingest.log"
echo -e " Spark 离线趋势 -> /tmp/spark-trend.log"
echo -e " Spark 模型训练 -> /tmp/spark-train.log"
echo -e " Spark 实时预测 -> /tmp/spark-predict.log"
echo -e " Spring Boot -> /tmp/backend.log"
echo ""
echo -e " ${CYAN}服务验证:${NC}"
echo -e " Flink UI -> http://master:8081"
echo -e " YARN UI -> http://slave1:8088"
echo -e " 后端接口 -> http://master:8080/api/history/temp7d"
echo -e " 前端大屏 -> http://192.168.36.100"
echo ""2.一键关闭项目脚本
#!/bin/bash
# =============================================================
# 大数据项目一键关闭脚本
# 运行节点:master
# 使用方式:chmod +x /opt/jars/stop-all.sh && ./opt/jars/stop-all.sh
# 停止顺序:与启动顺序相反,避免依赖服务先被关闭
# =============================================================
# ---------- 颜色定义 ----------
RED='\033[0;31m'
GREEN='\033[0;32m'
YELLOW='\033[1;33m'
BLUE='\033[0;34m'
CYAN='\033[0;36m'
NC='\033[0m'
# ---------- 工具函数 ----------
log_step() { echo ""; echo -e "${BLUE}========================================${NC}"; echo -e "${CYAN} $1${NC}"; echo -e "${BLUE}========================================${NC}"; }
log_info() { echo -e "${YELLOW}[INFO]${NC} $1"; }
log_ok() { echo -e "${GREEN}[OK]${NC} $1"; }
log_skip() { echo -e "${CYAN}[SKIP]${NC} $1(未在运行,跳过)"; }
log_error() { echo -e "${RED}[ERROR]${NC} $1"; }
wait_sec() { log_info "等待 $1 秒..."; sleep "$1"; }
# 检查本地是否有某个 jps 关键字对应的进程(用 jps 避免 pgrep 长命令行截断问题)
is_running_local() {
# 先尝试 jps 精确匹配(适用于 Java 进程)
# 若 jps 找不到则回退 pgrep(适用于 Python/Shell 进程)
source /etc/profile && jps 2>/dev/null | grep -qw "$1" 2>/dev/null || pgrep -f "$1" > /dev/null 2>&1
}
# 检查远程节点是否有某个 jps 关键字对应的进程
is_running_remote() {
local result
result=$(ssh "$1" "source /etc/profile && jps 2>/dev/null | grep -w '$2'" 2>/dev/null)
[ -n "$result" ]
}
# 用 pkill 停止本地进程,带超时等待确认
kill_local() {
local keyword="$1"
local name="$2"
if is_running_local "$keyword"; then
log_info "停止 $name..."
pkill -f "$keyword"
local i=0
while is_running_local "$keyword" && [ $i -lt 10 ]; do
sleep 1; i=$((i+1))
done
if is_running_local "$keyword"; then
log_info "$name 未响应,强制终止..."
pkill -9 -f "$keyword"
fi
log_ok "$name 已停止"
else
log_skip "$name"
fi
}
# 用 pkill 停止远程进程
kill_remote() {
local node="$1"
local keyword="$2"
local name="$3"
if is_running_remote "$node" "$keyword"; then
log_info "[$node] 停止 $name..."
ssh "$node" "pkill -f '$keyword' 2>/dev/null; sleep 2; pkill -9 -f '$keyword' 2>/dev/null; true"
log_ok "[$node] $name 已停止"
else
log_skip "[$node] $name"
fi
}
# ---------- 配置(与 start-all.sh 保持一致) ----------
SSH_ENV="source /etc/profile && "
SLAVE1="slave1"
SLAVE2="slave2"
KAFKA_CONFIG="/opt/apps/kafka/config/server.properties"
SIM_SCRIPT="01_device_status_sim.py"
SPARK_CLASS="com.demo.spark.DevicePredictStreamJob"
BACKEND_JAR="/opt/jars/smart-screen-backend-1.0.0-SNAPSHOT.jar"
FLINK_CLASS="com.demo.flink.RtMetricsSqlJob"
PID_FILE="/tmp/bigdata-pids.env"
# =============================================================
# 第 8 步(逆序):停止 Spring Boot 后端
# =============================================================
log_step "第 1 步(逆序):停止 Spring Boot 后端"
kill_local "$BACKEND_JAR" "Spring Boot 后端"
# =============================================================
# 第 7 步(逆序):停止 Spark ML 作业
# =============================================================
log_step "第 2 步(逆序):停止 Spark ML 作业"
kill_local "$SPARK_CLASS" "Spark ML 作业"
# 同时清理残留的 spark-submit 进程
is_running_local "spark-submit" && pkill -9 -f "spark-submit" 2>/dev/null
# =============================================================
# 第 6 步(逆序):取消 Flink 作业并停止 Flink 集群
# =============================================================
log_step "第 3 步(逆序):停止 Flink 作业 & 集群"
# 先通过 REST API 取消正在运行的 Flink 作业
log_info "查询并取消所有 Flink 作业..."
# 用 jq 解析,若无 jq 则用 grep 匹配 "jid":"xxxxx" 格式
JOBS=$(curl -s http://localhost:8081/jobs/overview 2>/dev/null \
| grep -o '"jid":"[^"]*"' | grep -o '[0-9a-f]\{32\}')
if [ -z "$JOBS" ]; then
log_skip "Flink 作业(无运行中的作业)"
else
for JOB_ID in $JOBS; do
log_info "取消 Flink 作业 ID: $JOB_ID"
curl -s -X PATCH "http://localhost:8081/jobs/${JOB_ID}?mode=cancel" > /dev/null
log_ok "作业 $JOB_ID 已取消"
done
wait_sec 3
fi
wait_sec 3
# 再停止 Flink 集群
if is_running_local "StandaloneSessionClusterEntrypoint"; then
log_info "停止 Flink 集群..."
source /etc/profile && stop-cluster.sh \
&& log_ok "Flink 集群已停止" \
|| log_error "Flink 集群停止失败"
else
log_skip "Flink 集群"
fi
# =============================================================
# 第 5 步(逆序):停止 Kafka 数据采集
# =============================================================
log_step "第 4 步(逆序):停止 Kafka 数据采集"
kill_local "$SIM_SCRIPT" "Kafka 数据采集(Python 模拟)"
# 同时停止 kafka-console-producer
kill_local "kafka-console-producer" "kafka-console-producer"
# =============================================================
# 第 3 步(逆序):停止 Hive Metastore
# =============================================================
log_step "第 5 步(逆序):停止 Hive Metastore"
kill_local "RunJar" "Hive Metastore"
# =============================================================
# 第 2 步(逆序):停止 Kafka 和 ZooKeeper
# =============================================================
log_step "第 6 步(逆序):停止 Kafka"
for NODE in master "$SLAVE1" "$SLAVE2"; do
if [ "$NODE" = "master" ]; then
KAFKA_PID=$(jps 2>/dev/null | grep -w 'Kafka' | awk '{print $1}')
if [ -n "$KAFKA_PID" ]; then
log_info "[$NODE] 停止 Kafka(PID=$KAFKA_PID)..."
kill -15 "$KAFKA_PID" 2>/dev/null
sleep 3
# 若还存活则强制终止
jps 2>/dev/null | grep -w 'Kafka' | awk '{print $1}' | xargs -r kill -9 2>/dev/null
sleep 1
STILL=$(jps 2>/dev/null | grep -w 'Kafka')
if [ -n "$STILL" ]; then
log_error "[$NODE] Kafka 停止失败,请手动处理"
else
log_ok "[$NODE] Kafka 已停止"
fi
else
log_skip "[$NODE] Kafka"
fi
else
KAFKA_PID=$(ssh "$NODE" "source /etc/profile && jps 2>/dev/null | grep -w 'Kafka' | awk '{print \$1}'" 2>/dev/null)
if [ -n "$KAFKA_PID" ]; then
log_info "[$NODE] 停止 Kafka(PID=$KAFKA_PID)..."
ssh "$NODE" "kill -15 $KAFKA_PID 2>/dev/null; sleep 3; kill -9 $KAFKA_PID 2>/dev/null; true"
log_ok "[$NODE] Kafka 已停止"
else
log_skip "[$NODE] Kafka"
fi
fi
done
wait_sec 3
log_step "第 7 步(逆序):停止 ZooKeeper"
# ZooKeeper 必须在 Kafka 完全停止后再关,否则 Kafka offset 可能丢失
for NODE in master "$SLAVE1" "$SLAVE2"; do
if [ "$NODE" = "master" ]; then
if is_running_local "QuorumPeerMain"; then
log_info "[$NODE] 停止 ZooKeeper..."
source /etc/profile && zkServer.sh stop \
&& log_ok "[$NODE] ZooKeeper 已停止" \
|| log_error "[$NODE] ZooKeeper 停止失败"
else
log_skip "[$NODE] ZooKeeper"
fi
else
if is_running_remote "$NODE" "QuorumPeerMain"; then
log_info "[$NODE] 停止 ZooKeeper..."
ssh "$NODE" "${SSH_ENV}zkServer.sh stop" \
&& log_ok "[$NODE] ZooKeeper 已停止" \
|| log_error "[$NODE] ZooKeeper 停止失败"
else
log_skip "[$NODE] ZooKeeper"
fi
fi
done
wait_sec 3
# =============================================================
# 第 1 步(逆序):停止 YARN 和 HDFS
# =============================================================
log_step "第 8 步(逆序):停止 YARN 和 HDFS"
if is_running_remote "$SLAVE1" "ResourceManager"; then
log_info "在 slave1 停止 YARN..."
ssh "$SLAVE1" "${SSH_ENV}stop-yarn.sh" \
&& log_ok "YARN 已停止" \
|| log_error "YARN 停止失败"
else
log_skip "YARN ResourceManager"
fi
wait_sec 3
if is_running_local "NameNode"; then
log_info "停止 HDFS..."
source /etc/profile && stop-dfs.sh \
&& log_ok "HDFS 已停止" \
|| log_error "HDFS 停止失败"
else
log_skip "HDFS NameNode"
fi
# =============================================================
# 清理 PID 文件
# =============================================================
if [ -f "$PID_FILE" ]; then
rm -f "$PID_FILE"
log_info "已清理 PID 文件:$PID_FILE"
fi
# =============================================================
# 回滚完成汇总
# =============================================================
echo ""
echo -e "${GREEN}============================================${NC}"
echo -e "${GREEN} ✅ 所有服务已停止!${NC}"
echo -e "${GREEN}============================================${NC}"
echo ""
echo -e " 各节点最终进程状态(通过 SSH 检查):"
for NODE in master "$SLAVE1" "$SLAVE2"; do
if [ "$NODE" = "master" ]; then
PROCS=$(source /etc/profile && jps 2>/dev/null | grep -v Jps)
else
PROCS=$(ssh "$NODE" "source /etc/profile && jps 2>/dev/null | grep -v Jps")
fi
echo -e " ${CYAN}[$NODE]${NC}"
if [ -z "$PROCS" ]; then
echo -e " (无 Java 进程)✅"
else
echo "$PROCS" | while read -r line; do
echo -e " ${YELLOW}$line${NC}"
done
fi
done
echo ""五、常见问题排查
| 现象 | 排查方向 |
|---|---|
| 大屏无数据 | Kafka 未启动 / 模拟脚本未运行 |
| MySQL 无数据 | Flink 作业未提交或已失败 |
| ClickHouse 预测为空 | Spark ML 作业未运行 |
| 接口请求报错 | Spring Boot 后端未启动 |
| 前端白屏 | 后端端口配置错误(默认 8080) |
| Flink 提交报类冲突 | 检查 flink-conf.yaml 类加载配置 |
| Hive 连接失败 | Metastore 端口 9083 未启动 |
六、系统数据流向