12.1 实验目标
掌握 Spark 实时读取 Kafka 数据的基本流程
学会用
when条件判断实现异常检测实现将告警数据实时写入 ClickHouse
12.2 数据流动说明
Kafka → Spark(解析JSON → 判断异常) → ClickHouse
12.3 ClickHouse 建表
-- 启动clickhouse clickhouse-client -m -- 创建表 CREATE TABLE IF NOT EXISTS iot_report.dwd_device_alert_detail ( device_id String, alert_type String, -- 注释:TEMP_HIGH / LOAD_HIGH / VOLTAGE_ABNORMAL alert_level String, -- 注释:HIGH / MEDIUM temperature Float64, load Float64, voltage Float64, alert_msg String, alert_time DateTime, dt Date ) ENGINE = MergeTree() PARTITION BY dt ORDER BY (device_id, alert_time);
12.4 告警规则
| 告警类型 | 触发条件 | 级别 |
|---|---|---|
| TEMP_HIGH | 温度 > 80°C | HIGH |
| LOAD_HIGH | 负载 > 90% | MEDIUM |
| VOLTAGE_ABNORMAL | 电压 < 180V 或 > 260V | MEDIUM |
同时满足多个条件时,只命中第一个满足的规则。
完整的代码
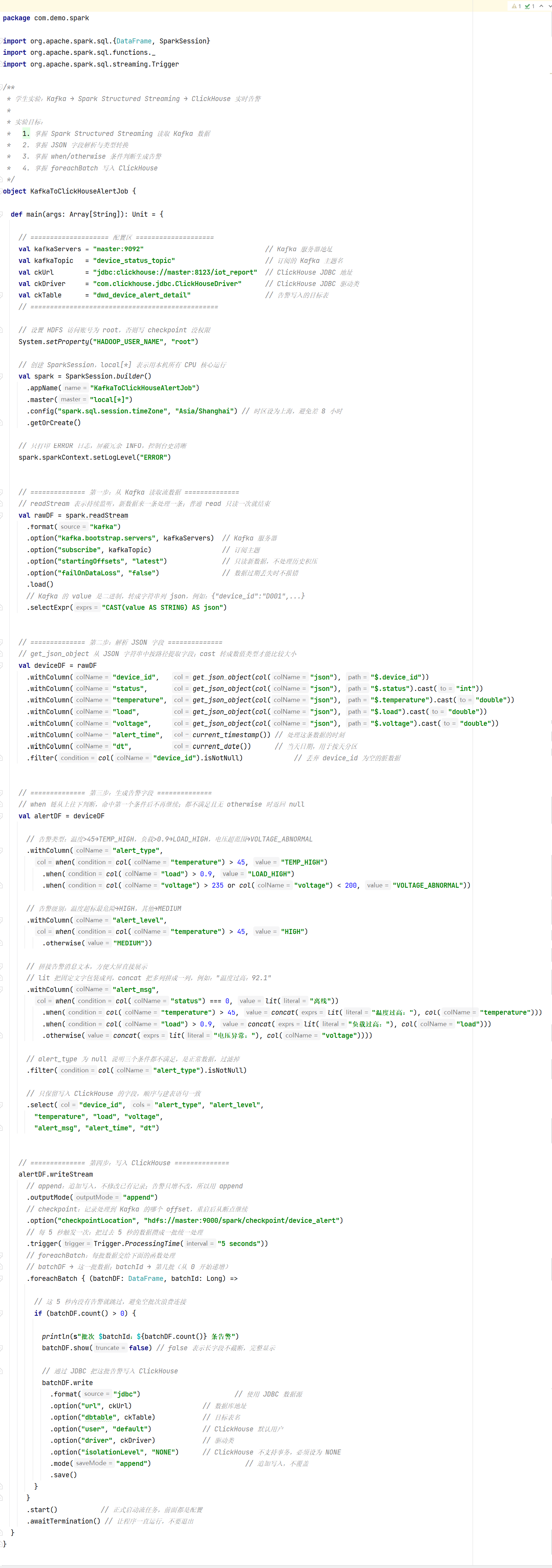
package com.demo.spark
import org.apache.spark.sql.{DataFrame, SparkSession}
import org.apache.spark.sql.functions._
import org.apache.spark.sql.streaming.Trigger
/**
* 学生实验:Kafka → Spark Structured Streaming → ClickHouse 实时告警
*
* 实验目标:
* 1. 掌握 Spark Structured Streaming 读取 Kafka 数据
* 2. 掌握 JSON 字段解析与类型转换
* 3. 掌握 when/otherwise 条件判断生成告警
* 4. 掌握 foreachBatch 写入 ClickHouse
*
* 共 40 个 TODO 填空任务,请将每个 _________ 替换为正确代码
*/
object KafkaToClickHouseAlertJob {
def main(args: Array[String]): Unit = {
// ==================== 配置区 ====================
// TODO 1: 填写 Kafka 服务器地址(host:port 格式)
val kafkaServers = "_________"
// TODO 2: 填写要订阅的 Kafka 主题名
val kafkaTopic = "_________"
// TODO 3: 填写 ClickHouse 的 JDBC 连接地址(库名 iot_report)
val ckUrl = "_________"
// TODO 4: 填写 ClickHouse 的 JDBC 驱动类全限定名
val ckDriver = "_________"
// TODO 5: 填写要写入的 ClickHouse 目标表名
val ckTable = "_________"
// ================================================
// TODO 6: 设置 HADOOP_USER_NAME 系统属性为 root(用于 HDFS checkpoint 写入权限)
System.setProperty("_________", "_________")
// TODO 7: 创建 SparkSession,链式调用的起点方法
val spark = SparkSession._________()
// TODO 8: 设置应用名称为 "KafkaToClickHouseAlertJob"
._________("KafkaToClickHouseAlertJob")
// TODO 9: 设置运行模式为本机所有核心
.master("_________")
// TODO 10: 设置时区为上海,避免时间相差 8 小时
.config("spark.sql.session.timeZone", "_________")
// TODO 11: 获取或创建 SparkSession 实例
._________()
// TODO 12: 把日志级别调到 ERROR,屏蔽冗余 INFO
spark.sparkContext.setLogLevel("_________")
// ============== 第一步:从 Kafka 读取流数据 ==============
// TODO 13: 使用流式读取 API(提示:与普通 read 不同,会持续监听)
val rawDF = spark._________
// TODO 14: 指定数据源格式为 kafka
.format("_________")
.option("kafka.bootstrap.servers", kafkaServers)
// TODO 15: 订阅主题,参数名是什么?
.option("_________", kafkaTopic)
// TODO 16: 只消费最新数据,不读历史,offset 应该填什么?
.option("startingOffsets", "_________")
.option("failOnDataLoss", "false")
.load()
// TODO 17: 把 Kafka 的 value(二进制)转成字符串列 json
.selectExpr("_________ AS json")
// ============== 第二步:解析 JSON 字段 ==============
val deviceDF = rawDF
// TODO 18: 用 get_json_object 提取 device_id 字段
.withColumn("device_id", get_json_object(col("json"), "_________"))
// TODO 19: 提取 status 并转为 int 类型
.withColumn("status", get_json_object(col("json"), "$.status").cast("_________"))
.withColumn("temperature", get_json_object(col("json"), "$.temperature").cast("double"))
.withColumn("load", get_json_object(col("json"), "$.load").cast("double"))
.withColumn("voltage", get_json_object(col("json"), "$.voltage").cast("double"))
// TODO 20: 添加 alert_time 列,值为当前时间戳的内置函数
.withColumn("alert_time", _________())
// TODO 21: 添加 dt 列,值为当前日期的内置函数(按天分区用)
.withColumn("dt", _________())
// TODO 22: 过滤掉 device_id 为空的脏数据
.filter(col("device_id")._________)
// ============== 第三步:生成告警字段 ==============
val alertDF = deviceDF
// 告警类型判断:温度>45→TEMP_HIGH,负载>0.9→LOAD_HIGH,电压异常→VOLTAGE_ABNORMAL
.withColumn("alert_type",
// TODO 23: 条件判断的起始函数(类似 SQL 的 CASE WHEN)
_________(col("temperature") > 45, "TEMP_HIGH")
// TODO 24: 第二个条件:负载大于 0.9
._________(col("load") > 0.9, "LOAD_HIGH")
// TODO 25: 第三个条件:电压 > 235 或 < 200(使用 or 连接)
.when(col("voltage") > 235 _________ col("voltage") < 200, "VOLTAGE_ABNORMAL"))
// 告警级别:温度超标→HIGH,其他→MEDIUM
.withColumn("alert_level",
when(col("temperature") > 45, "HIGH")
// TODO 26: 都不满足时返回 MEDIUM 的方法名
._________("MEDIUM"))
// 拼接告警消息文本
.withColumn("alert_msg",
// TODO 27: status 等于 0 的判断(DataFrame API 中三等号)
when(col("status") _________ 0, lit("离线"))
// TODO 28: 用 concat 拼接固定文字和数值列,固定文字用什么函数包装?
.when(col("temperature") > 45, concat(_________("温度过高:"), col("temperature")))
.when(col("load") > 0.9, concat(lit("负载过高:"), col("load")))
.otherwise(concat(lit("电压异常:"), col("voltage"))))
// TODO 29: 过滤掉正常数据,保留 alert_type 不为 null 的行
.filter(col("alert_type")._________)
// TODO 30: 选出最终要写入 ClickHouse 的 9 个字段(按建表顺序)
._________("device_id", "alert_type", "alert_level",
"temperature", "load", "voltage",
"alert_msg", "alert_time", "dt")
// ============== 第四步:写入 ClickHouse ==============
// TODO 31: 启动流式写出 API
alertDF._________
// TODO 32: 输出模式(告警只增不改,应该用哪种?append/update/complete)
.outputMode("_________")
// TODO 33: 设置 checkpoint 路径,用于故障恢复
.option("_________", "hdfs://master:9000/spark/checkpoint/device_alert")
// TODO 34: 每 5 秒触发一次微批处理
.trigger(Trigger._________("5 seconds"))
// TODO 35: 自定义每批处理逻辑的方法名
._________ { (batchDF: DataFrame, batchId: Long) =>
// TODO 36: 判断这批数据是否非空(统计行数 > 0)
if (batchDF._________ > 0) {
println(s"批次 $batchId:${batchDF.count()} 条告警")
batchDF.show(false)
// 把告警数据通过 JDBC 写入 ClickHouse
batchDF.write
// TODO 37: 写入格式为 jdbc
.format("_________")
.option("url", ckUrl)
// TODO 38: 指定目标表名的参数键
.option("_________", ckTable)
.option("user", "default")
.option("driver", ckDriver)
// ClickHouse 不支持事务,必须设为 NONE
.option("isolationLevel", "NONE")
// TODO 39: 写入模式为追加
.mode("_________")
.save()
}
}
.start()
// TODO 40: 让流任务持续运行不退出的方法
._________()
}
}参考源码:
12.6 启动环境
(1)启动Hadoop
# 启动 Hadoop
start-dfs.sh # 在master操作
start-yarn.sh # 在slave1操作
(2)启动Kafka
# 在master/slave1/slave2启动 ZooKeeper
zkServer.sh start
# 在master/slave1/slave2检查 ZooKeeper状态
zkServer.sh status
# 在master/slave1/slave2启动 Kafka
kafka-server-start.sh -daemon /opt/apps/kafka/config/server.properties
(3)写入状态流数据到 Kafka
# 在master节点中操作【新开窗口】
cd /opt/datas
# 启动设备状态模拟脚本,并将数据写入 Kafka
python 01_device_status_sim.py | \
kafka-console-producer.sh --broker-list master:9092 --topic device_status_topic
(4)验证实时数据
# 从 device_status_topic 主题中实时消费(查看)Kafka中的设备状态数据流
kafka-console-consumer.sh --bootstrap-server master:9092 \
--topic device_status_topic
12.6 IDEA运行代码
12.7 验证结果
# 在clickhouse中查看写入的告警数据
clickhouse-client --query \
"SELECT device_id, alert_type, alert_level, alert_msg, alert_time
FROM iot_report.dwd_device_alert_detail
ORDER BY alert_time DESC LIMIT 10"
12.8 打包运行
# 方法一:本地模式(调试用)
spark-submit \
--class com.demo.spark.KafkaToClickHouseAlertJob \
--master local[1] \
/opt/jars/spark-job-1.0.0.jar