补充实验:此实验的数据没有呈现在数据大屏
11.1 实验目标
1.掌握 Spark 实时流计算的基本开发流程,理解 Structured Streaming 微批处理机制。
2.学会使用 Spark 实时消费 Kafka 中的设备 JSON 数据,并完成字段解析与数据过滤。
3.掌握基于流数据的实时聚合统计,实时统计:平均温度、最高温度、平均负载、平均电压。
4.实现实时计算结果通过 JDBC 写入 ClickHouse,为大数据大屏提供标准统计数据源。
5.理解 Kafka → Spark → ClickHouse 实时数仓架构,提升大数据综合实战能力。
和前两张图的对比:
| 第一张 | 第二张 | 第三张(这张) | |
|---|---|---|---|
| 数据源 | Kafka | Hive | Kafka |
| 目的地 | Hive | ClickHouse | ClickHouse |
| 模式 | 流处理 | 批处理 | 流处理 |
| 触发间隔 | 10秒 | 手动运行 | 5秒 |
| 用途 | 存原始数据 | 离线报表 | 实时大屏 |
11.2 数据流动说明
设备数据 → Kafka 消息缓存 → Spark 实时解析与聚合统计 → ClickHouse 结果入库,形成完整的实时数仓入库链路。
11.3 ClickHouse 表设计
-- 1.启动多行模式(在master中操作) clickhouse-client -m -- 2.检查 iot_report 数据库是否存在 show databases; -- 3.选择数据库 use iot_report; -- 4.创建实时设备统计报表 CREATE TABLE IF NOT EXISTS iot_report.dws_device_real_report ( device_id String, dt Date, avg_temp Float64, max_temp Float64, avg_load Float64, avg_voltage Float64 ) ENGINE = MergeTree() PARTITION BY dt ORDER BY (device_id, dt); -- 5.查看数据表 show tables;
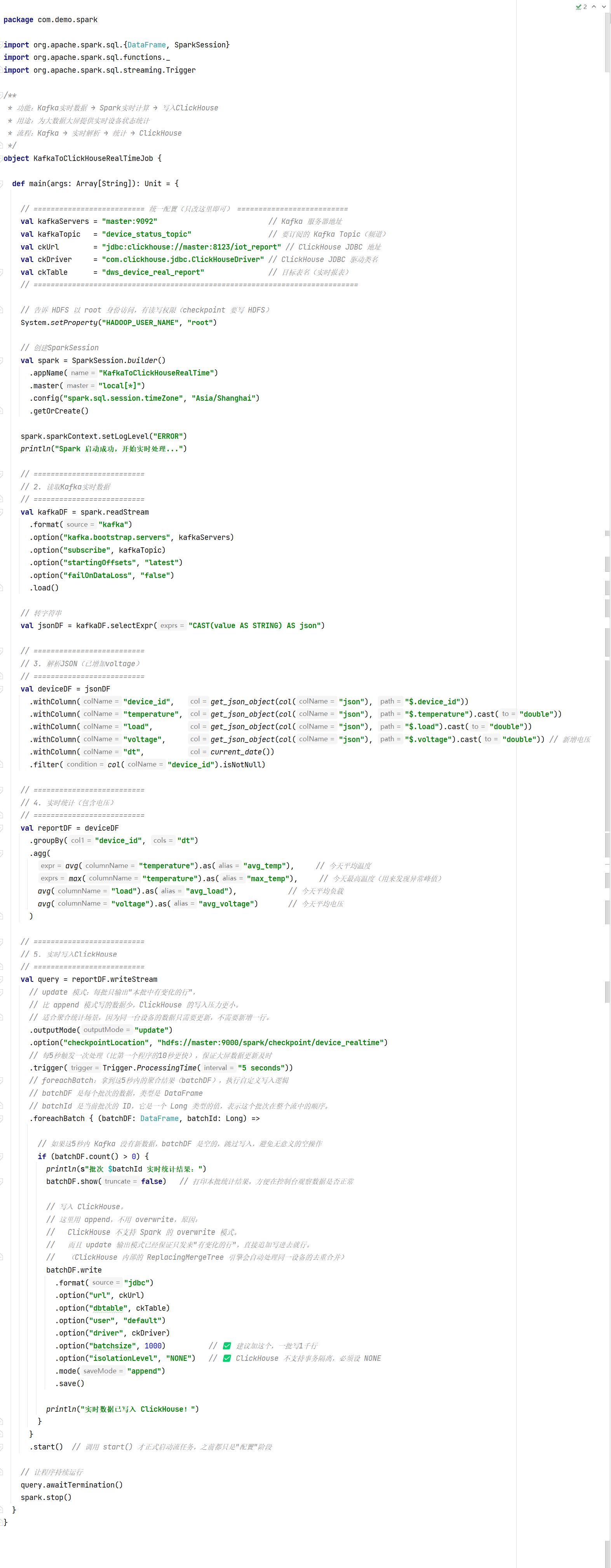
11.4 完整代码
完成代码填空
package com.demo.spark
// TODO 1: 导入 DataFrame 和 SparkSession(填写正确的类名)
import org.apache.spark.sql.{__________, SparkSession}
import org.apache.spark.sql.functions._
// TODO 2: 导入流式触发器 Trigger(填写正确的类名)
import org.apache.spark.sql.streaming.__________
object KafkaToClickHouseRealTimeJob {
def main(args: Array[String]): Unit = {
// ========================== 统一配置 ==========================
val kafkaServers = "master:9092"
val kafkaTopic = "device_status_topic"
val ckUrl = "jdbc:clickhouse://master:8123/iot_report"
val ckDriver = "com.clickhouse.jdbc.ClickHouseDriver"
val ckTable = "dws_device_real_report"
// =============================================================
// TODO 3: 设置 HADOOP_USER_NAME 系统属性 key(填写环境变量名)
System.setProperty("__________", "root")
// TODO 4: 创建 SparkSession 的入口类(填写类名)
val spark = __________.builder()
// TODO 5: 设置应用名称为 "KafkaToClickHouseRealTime"
.appName("__________")
// TODO 6: 设置运行模式为本地所有核心
.master("__________")
// TODO 7: 设置时区为 "Asia/Shanghai",避免时间差 8 小时
.config("spark.sql.session.timeZone", "__________")
// TODO 8: 补全获取或创建 SparkSession 的方法名
.__________()
// TODO 9: 设置日志级别屏蔽 INFO,只保留 ERROR 日志
spark.sparkContext.setLogLevel("__________")
println("Spark 启动成功,开始实时处理...")
// ==========================
// 2. 读取 Kafka 实时数据
// ==========================
// TODO 10: 持续读取数据应使用 readStream 而非 read,填写正确方法名
val kafkaDF = spark.__________
// TODO 11: 数据源类型设置为 kafka
.format("__________")
// TODO 12: 配置 Kafka 服务器地址,填写正确的 option key
.option("__________", kafkaServers)
// TODO 13: 订阅 Kafka Topic,填写正确的 option key
.option("__________", kafkaTopic)
// TODO 14: 启动时只读取最新数据,不处理历史积压数据(填写偏移量策略)
.option("startingOffsets", "__________")
// TODO 15: 数据丢失时不报错继续运行(填写 true 或 false)
.option("failOnDataLoss", "__________")
.load()
// TODO 16: 把 Kafka 的二进制 value 字段转为字符串,列名为 json
val jsonDF = kafkaDF.selectExpr("__________")
// ==========================
// 3. 解析 JSON(已增加 voltage)
// ==========================
val deviceDF = jsonDF
// TODO 17: 从 json 列中提取 device_id 字段(补全 JSON 路径,以 $ 开头)
.withColumn("device_id", get_json_object(col("json"), "__________"))
// TODO 18: 提取 temperature 字段并转为 double 类型(补全 JSON 路径)
.withColumn("temperature", get_json_object(col("json"), "__________").cast("double"))
.withColumn("load", get_json_object(col("json"), "$.load").cast("double"))
// TODO 19: 提取 voltage 字段并转为 double 类型(补全 cast 的目标类型)
.withColumn("voltage", get_json_object(col("json"), "$.voltage").cast("__________"))
// TODO 20: 新增 dt 列,值为当前日期,用于按天分区(使用内置函数)
.withColumn("dt", __________)
// TODO 21: 过滤掉 device_id 为 null 的脏数据(填写判断方法名)
.filter(col("device_id").__________)
// ==========================
// 4. 实时统计(按设备 + 日期分组)
// ==========================
// TODO 22: 按 device_id 和 dt 进行分组聚合(填写分组方法名)
val reportDF = deviceDF
.__________("device_id", "dt")
.agg(
// TODO 23: 计算今日平均温度,列名为 avg_temp(填写聚合函数)
__________("temperature").as("avg_temp"),
// TODO 24: 计算今日最高温度,列名为 max_temp(填写聚合函数)
__________("temperature").as("max_temp"),
avg("load").as("avg_load"),
// TODO 25: 计算今日平均电压,列名为 avg_voltage(填写聚合函数)
__________("voltage").as("avg_voltage")
)
// ==========================
// 5. 实时写入 ClickHouse
// ==========================
val query = reportDF.writeStream
// TODO 26: 聚合统计场景使用 update 模式,只输出有变化的行(不能用 complete/append)
.outputMode("__________")
// TODO 27: 补全 checkpoint 配置的 option key 名称
.option("__________", "hdfs://master:9000/spark/checkpoint/device_realtime")
// TODO 28: 每 5 秒触发一次批处理(带时间单位,如 "5 seconds")
.trigger(Trigger.ProcessingTime("__________"))
.foreachBatch { (batchDF: DataFrame, batchId: Long) =>
if (batchDF.count() > 0) {
println(s"批次 $batchId 实时统计结果:")
batchDF.show(false)
batchDF.write
.format("jdbc")
.option("url", ckUrl)
.option("dbtable", ckTable)
.option("user", "default")
.option("driver", ckDriver)
// TODO 29: 一批写入 1000 行,提升写入性能(填写 option 的值)
.option("batchsize", __________)
// TODO 30: ClickHouse 不支持事务,isolationLevel 必须设为 NONE
.option("isolationLevel", "__________")
.mode("append")
.save()
println("实时数据已写入 ClickHouse!")
}
}
.start()
query.awaitTermination()
spark.stop()
}
}参考源代码
11.5 启动环境
(1)启动Hadoop
# 启动 Hadoop start-dfs.sh # 在master操作 start-yarn.sh # 在slave1操作
(2)启动Kafka
# 在master/slave1/slave2启动 ZooKeeper zkServer.sh start # 在master/slave1/slave2检查 ZooKeeper状态 zkServer.sh status # 在master/slave1/slave2启动 Kafka kafka-server-start.sh -daemon /opt/apps/kafka/config/server.properties
(3)写入状态流数据到 Kafka
# 在master节点中操作【新开窗口】 cd /opt/datas # 启动设备状态模拟脚本,并将数据写入 Kafka python 01_device_status_sim.py | \ kafka-console-producer.sh --broker-list master:9092 --topic device_status_topic
(4)验证实时数据
# 从 device_status_topic 主题中实时消费(查看)Kafka中的设备状态数据流 kafka-console-consumer.sh --bootstrap-server master:9092 \ --topic device_status_topic
11.6 IDEA运行代码
11.7 验证结果
-- 查看clickhouse中的dws_temp_trend_day表数据 -- 实时统计:平均温度、最高温度、平均负载、平均电压 SELECT * FROM iot_report.dws_device_real_report ORDER BY dt;
11.8 打包运行
# 方法一:本地模式(调试用) spark-submit \ --class com.demo.spark.KafkaToClickHouseRealTimeJob \ --master local[1] \ /opt/jars/spark-job-1.0.0.jar