8.1 实验任务
使用 Spark 连接 Hive,在 IDEA 中查看 Hive 数据库中的表,并显示各表的前 3 条数据。
8.2 创建 Spark 项目
(1)在IDEA中创建 spark-ods-ingest 项目

创建 scala 模块文件路径:
src/main/scala/com/demo/spark/HiveTablePreviewJob.scala
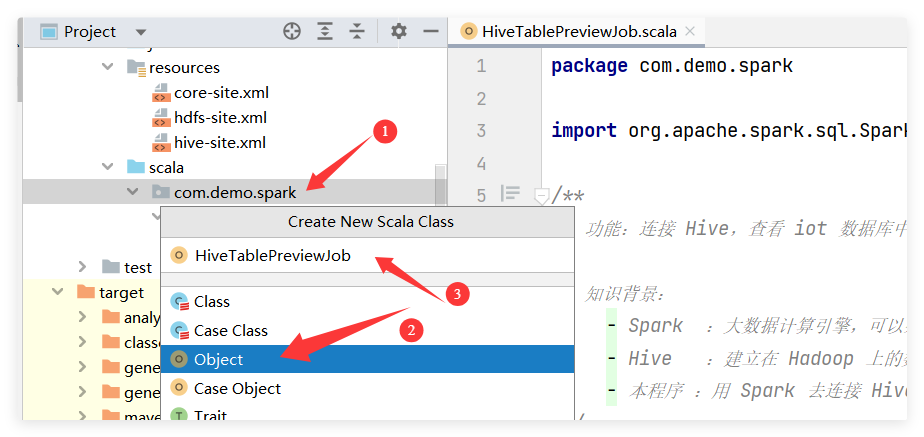
(2)确认有 scala 目录
项目结构应为:
src
└── main
├── java
├── resources
└── scala ← 如果不存在则创建:1.右键 main → New → Directory → 输入 scala
2.右键 scala 文件夹 → 选择Mark Directory as → Sources Root
scala 文件夹会变成📘 蓝色文件夹图标,被识别为源码目录
(3)创建包
右键 scala → New → Package
输入:
com.demo.spark
(4)创建 Scala 类
右键 com.demo.spark → New → Scala Class
会弹出创建窗口,选择:
Object
然后输入文件名:
HiveTablePreviewJob
⚠ 注意:
不要写
.scala只写类名
选择 Object(因为需要 main 方法)
(5)生成模板代码
创建完成后,自动生成模块框架,稍后编写代码到此 Object 中

(6)复制 hive-site.xml 文件到 IntelliJ IDEA 中
在 IntelliJ IDEA 中,将配置好的 hive-site.xml 文件复制到IDEA项目的 resources 目录下,以确保 Spark 能够读取 Hive 配置信息并正确连接到 Hive。
(7)复制 core-site.xml和 hdfs-site.xml 文件到 IntelliJ IDEA 中
同样地,将Hadoop的配置文件 core-site.xml 和 hdfs-site.xml 文件复制到IDEA项目的 resources 目录下。这些配置文件是在IDEA中运行项目时, Spark 连接到 HDFS 所必需的,它们提供了 HDFS 的核心配置信息,包括 NameNode 的地址和文件系统的基本配置。因为下面的代码把检查点设置到了HDFS路径上

8.3 Pom文件
<!-- Maven 项目配置文件(核心文件) -->
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://www.apache.org/xsd/maven-4.0.0.xsd">
<!-- 模型版本(固定写法) -->
<modelVersion>4.0.0</modelVersion>
<!-- 项目基本信息 -->
<groupId>com.demo</groupId> <!-- 组织名(公司/包名) -->
<artifactId>spark-job</artifactId> <!-- 项目名 -->
<version>1.0.0</version> <!-- 项目版本 -->
<name>spark-job</name>
<!-- ===================== -->
<!-- 版本统一管理(非常重要) -->
<!-- ===================== -->
<properties>
<!-- Spark 版本 -->
<spark.version>3.1.1</spark.version>
<!-- Scala 版本(必须与 Spark 匹配) -->
<scala.binary.version>2.12</scala.binary.version>
<scala.version>2.12.18</scala.version>
<!-- Kafka 客户端版本 -->
<kafka.clients.version>2.4.1</kafka.clients.version>
<!-- Java 版本(必须 1.8) -->
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<!-- 编码格式 -->
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<!-- ===================== -->
<!-- 依赖包(核心) -->
<!-- ===================== -->
<dependencies>
<!-- Scala 基础库(必须) -->
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<!-- ===== Spark 核心组件 ===== -->
<!-- Spark 核心(必须) -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_${scala.binary.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<!-- Spark SQL(做数据分析) -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_${scala.binary.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<!-- Spark Hive(读取 Hive 表) -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_${scala.binary.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<!-- Spark MLlib(机器学习) -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-mllib_${scala.binary.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<!-- ===== Kafka 相关 ===== -->
<!-- Spark 读取 Kafka(流处理) -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql-kafka-0-10_${scala.binary.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<!-- Kafka Token(安全/认证用) -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-token-provider-kafka-0-10_${scala.binary.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<!-- Kafka 客户端 -->
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>${kafka.clients.version}</version>
</dependency>
<!-- ===== ClickHouse 数据库 ===== -->
<!-- ClickHouse JDBC 驱动 -->
<dependency>
<groupId>com.clickhouse</groupId>
<artifactId>clickhouse-jdbc</artifactId>
<version>0.6.0</version>
</dependency>
<!-- Http 组件(ClickHouse 依赖) -->
<dependency>
<groupId>org.apache.httpcomponents.client5</groupId>
<artifactId>httpclient5</artifactId>
<version>5.2.1</version>
</dependency>
<!-- HTTP 底层协议支持 -->
<dependency>
<groupId>org.apache.httpcomponents.core5</groupId>
<artifactId>httpcore5</artifactId>
<version>5.2.1</version>
</dependency>
<!-- ===== 日志组件 ===== -->
<!-- 日志桥接(slf4j -> log4j2) -->
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-slf4j-impl</artifactId>
<version>2.17.2</version>
</dependency>
<!-- 日志核心 -->
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>2.17.2</version>
</dependency>
</dependencies>
<!-- ===================== -->
<!-- 构建插件配置 -->
<!-- 作用:负责 Scala/Java 编译,以及项目打包 -->
<!-- ===================== -->
<build>
<plugins>
<!-- Scala 编译插件:负责编译 src/main/scala 下的 Scala 代码 -->
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>4.8.1</version>
<executions>
<!-- 编译主程序 -->
<execution>
<id>scala-compile</id>
<phase>process-resources</phase>
<goals>
<goal>add-source</goal> <!-- 添加 Scala 源码目录 -->
<goal>compile</goal> <!-- 编译 Scala -->
</goals>
</execution>
<!-- 编译测试代码 -->
<execution>
<id>scala-test-compile</id>
<phase>process-test-resources</phase>
<goals>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
<!-- 指定 Scala 版本 -->
<configuration>
<scalaVersion>${scala.version}</scalaVersion>
</configuration>
</plugin>
<!-- Java 编译插件:负责编译 Java 代码,并指定 JDK 版本和编码 -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.11.0</version>
<configuration>
<source>${maven.compiler.source}</source> <!-- Java版本 -->
<target>${maven.compiler.target}</target>
<encoding>${project.build.sourceEncoding}</encoding>
</configuration>
</plugin>
<!-- 打包插件:把依赖一起打进 jar,生成可直接运行的 fat jar -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>3.5.0</version>
<executions>
<execution>
<!-- 在 package 阶段执行 -->
<phase>package</phase>
<goals>
<goal>shade</goal> <!-- 打 fat jar -->
</goals>
<configuration>
<!-- 生成精简版 dependency-reduced-pom.xml -->
<createDependencyReducedPom>true</createDependencyReducedPom>
<!-- 过滤签名文件,避免打包冲突 -->
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
<!-- 合并 META-INF/services,避免 SPI 相关文件被覆盖 -->
<transformers>
<transformer implementation="org.apache.maven.plugins.shade.resource.ServicesResourceTransformer"/>
</transformers>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>8.4 启动环境
(1)启动大数据环境
# 启动 Hadoop start-dfs.sh # 在master操作 start-yarn.sh # 在slave1操作 # 启动 Hive 元数据服务 hive --service metastore & # 启动 Hive 客户端 hive
(2)确认 Hive 表已创建
USE iot; SHOW TABLES;
确保存在表:
ods_device_status_di
8.5 完整代码
