大数据综合实训项目:设备运行状态监控与风险预测可视化大屏
第五章:Flink 实时计算与指标统计
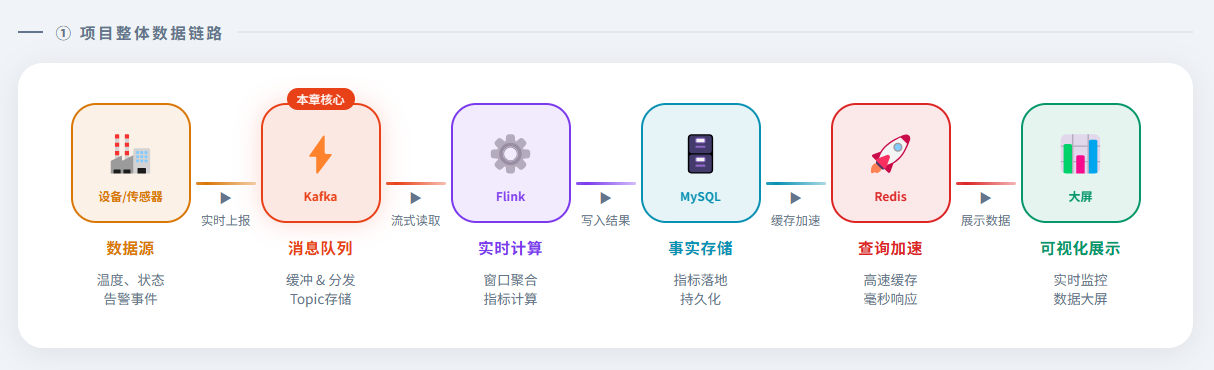
Kafka 采集数据 → Flink 实时计算 → MySQL 事实存储 → Redis 查询加速 → 大屏展示结果
一、实验背景(应用场景)
在现代企业中,随着设备和传感器的普及,产生了海量的数据。为了实现设备和业务的实时监控,企业需要能够实时计算和分析这些数据。Flink作为一种强大的实时流处理框架,能够对实时数据进行高效计算,并产生所需的核心指标。
应用场景:
- 企业需要实时监控生产设备的状态,基于传感器采集的数据进行指标计算(如设备运行情况、负载、温度等),实时做出决策。
- 在电商平台,实时统计用户的点击量、购买量等核心指标,用于优化商品推荐和营销策略。
- 在金融领域,通过实时监控交易数据,计算指标以识别潜在的风险交易,防止金融诈骗。
本章将介绍如何使用Flink进行实时流数据的计算和指标统计。通过对数据流进行窗口处理,我们可以根据设定的时间窗口计算出实时指标,例如平均温度、设备在线时长等。这些计算结果将直接用于后续的数据展示和业务决策。
本章的核心目标是让学生理解如何实时计算数据指标,并将计算结果落地,为后续的实时数据展示和业务优化提供支持。
二、教学目标
1. 知识目标
学生能够理解:
Flink 在项目中的角色(实时计算引擎)
流计算与批计算的根本区别
流计算是“数据一来就算”,批计算是“数据攒一堆再一起算”。
为什么实时计算一定要窗口
因为实时数据是“无限流”,必须按时间切成一段一段才能统计。
常见实时指标(在线数 / 告警数 / 趋势 / TopN)的业务含义
2. 能力目标
学生能够:
- 使用 Flink SQL 从 Kafka 读取实时数据
- 使用窗口完成实时统计
- 将实时计算结果写入Mysql
3. 素养目标
- 建立“指标口径意识”
- 理解“算什么比怎么写更重要”
- 形成企业级实时计算思维
三、教学重点与难点
1. 教学重点
Flink SQL 的整体计算流程
对 Kafka 里不断进来的设备数据,进行实时统计。普通 SQL 是查“已经存好的数据”,Flink SQL 是算“正在不断产生的数据”。
每10秒统计在线设备数
每10秒统计告警数量
每30秒算平均温度
每1分钟算告警Top5

Kafka → Flink → 结果表 的链路理解
窗口统计思想
把连续不断的数据,按时间切成一段一段来计算。
核心思想:时间分段 + 分段聚合
2. 教学难点
- 不理解“窗口”的必要性
- 把 Flink 当成 Spark 用
- 算出了数,但不知道业务含义
四、Flink 基础
1. Flink 的核心作用
在本项目中,Flink 主要负责:
- 从 Kafka 读取实时流数据
- 进行在线窗口计算
- 生成实时业务指标
- 将结果写入Mysql
2. Flink 与 Spark 的分工区别
| 技术 | 主要用途 | 特点 |
|---|---|---|
| Flink | 实时计算 | 低延迟、持续运行不停止 |
| Spark | 离线计算 | 批量处理、历史分析 |
五、本章实时指标
本章围绕 4 个最典型、最常见的实时指标 展开:
| 指标 | 数据来源 | MySQL 表 | 说明 |
|---|---|---|---|
| 实时在线设备数 | device_status_topic | rt_kpi_online_10s | 当前多少设备在线 |
| 实时温度趋势 | device_status_topic | rt_temp_trend_10s | 温度变化情况 |
| 实时告警数量 | device_status_topic(规则推导) | rt_kpi_alarm_10s | 当前时间段告警次数 |
| 实时告警 Top5 | device_status_topic(规则推导) | rt_alarm_top5_1m | 哪些设备告警最多 |
六、实验一:使用 Flink SQL 读取 Kafka 数据并计算实时指标
6.1 实验场景
在现代企业中,实时数据流处理对于监控设备、交易、用户行为等至关重要。在生产环境中,数据需要通过流处理系统实时计算和生成各种业务指标。Kafka作为消息队列系统,承担着实时数据传输的任务,Flink SQL作为强大的流处理工具,负责对数据进行实时计算,生成并输出核心指标。
本实验的应用场景是将Kafka中的实时数据通过Flink SQL进行处理,计算并输出实时业务指标。实验中,学生将学习如何配置Flink SQL Client,连接Kafka数据源,编写SQL进行流式数据计算,并验证实时计算结果的准确性。数据通过窗口计算,实时输出,并最终存储到数据库中进行后续分析和展示。
6.2 实验目标与成果
- Python → Kafka → Flink SQL client:通过Python模拟数据,发送到Kafka,使用Flink SQL Client读取Kafka中的数据并进行窗口计算。
- 配置 Flink SQL Client,连接 Kafka 数据源:在Flink SQL Client中配置Kafka连接,确保数据能够实时流入。
- 编写 SQL 查询流式数据并进行计算:使用Flink SQL编写SQL查询,计算实时数据的核心指标。
- 计算四类核心实时指标:计算并验证四类核心业务指标(如设备状态、温度、负载、告警等)。
- 验证数据流入与实时计算结果的正确性:确保实时数据流入Kafka并能正确流入Flink进行计算,验证计算结果的正确性。
- 临时会话验证模式:本实验采用Flink SQL Client进行临时会话验证。注意,关闭SQL Client后表的数据会消失,适用于测试和实验验证。
6.3 实验环境准备
6.3.1 添加依赖(Kafka Connector)
背景说明
使用 在 Flink SQL Client 里手写 SQL读取 Kafka 数据 时,Flink 默认不包含 Kafka Connector,需手动添加对应的 Connector JAR。
配置要求
Kafka Connector 的 JAR 包必须放置在 Flink 的 lib 目录中,并保证 所有 Flink 节点(master / slave1 / slave2)三个节点环境一致。
操作说明
将 flink-sql-connector-kafka_2.12-1.15.4.jar 复制到所有 Flink 节点(master / slave1 / slave2)的 $FLINK_HOME/lib/ 目录下。
常见问题说明
若某个节点缺少该 JAR,Flink 作业运行时将出现 ClassNotFoundException 错误。
6.3.2 启动 Flink 集群与 SQL Client
# 在 master 启动 Flink 集群
start-cluster.sh
# 在 master 启动 Flink SQL 交互客户端
sql-client.sh进入后看到下面提示符:
Flink SQL>6.3.3 Kafka 源表定义
Kafka 源表:
将 Kafka Topic 的实时消息映射为 Flink SQL 的**动态表**,用于查询与窗口计算。该表本身不保存数据,只负责定义数据格式、时间字段与水位线,作为实时计算的输入入口。
在当前 Flink SQL 会话中,执行下面
CREATE TABLE语句,注册 Kafka 源表。
注意:若未使用 HiveCatalog/JDBC Catalog 等持久化 Catalog,这些表属于会话级对象;关闭sql-client.sh(或会话结束)后表定义会消失,需要重新执行建表脚本。1.Kafka中的JSON数据示例(真实消息格式)
{ "event_type": "device_status", "device_id": "device-001", "status": 1, "temperature": 26.5, "load": 0.63, "voltage": 221.3, "event_time": "2026-03-09 10:00:05" }2.device_status 表结构(二维表说明)
字段名 数据类型 含义说明 示例 event_type STRING 事件类型(设备状态上报) device_status device_id STRING 设备编号 device-001 status INT 设备状态(1在线 / 0离线) 1 temperature DOUBLE 当前温度(℃) 26.5 load DOUBLE 设备负载 0.63 voltage DOUBLE 设备电压(V) 221.3 event_time STRING 设备上报时间(字符串) 2026-03-09 10:00:05 ts TIMESTAMP 计算列:转换后的时间字段 2026-03-09 10:00:05 3.device_status 示例数据(模拟设备实时数据)
event_type device_id status temperature load voltage event_time ts device_status device-001 1 25.6 0.42 219.8 2026-03-09 10:00:01 2026-03-09 10:00:01 device_status device-002 1 27.3 0.58 221.5 2026-03-09 10:00:02 2026-03-09 10:00:02 device_status device-003 1 26.8 0.61 220.7 2026-03-09 10:00:03 2026-03-09 10:00:03 device_status device-004 1 29.1 0.72 222.0 2026-03-09 10:00:04 2026-03-09 10:00:04 device_status device-005 0 30.4 0.35 218.6 2026-03-09 10:00:05 2026-03-09 10:00:05 device_status device-006 1 28.9 0.66 223.4 2026-03-09 10:00:06 2026-03-09 10:00:06 device_status device-007 1 27.1 0.59 221.2 2026-03-09 10:00:07 2026-03-09 10:00:07 device_status device-008 1 31.5 0.82 224.1 2026-03-09 10:00:08 2026-03-09 10:00:08
-- 说明:若未使用 HiveCatalog,表默认创建在default_catalog.default_database 中(Flink 内部默认库)
-- Catalog 是表的元数据管理中心,用来管理库和表的结构信息,不存储实际数据。
-- Flink 默认使用的是内存中的 Catalog(default_catalog),不会持久化到外部元数据系统。
-- 设备状态流数据表(对接 Kafka 的主题 device_status_topic)
-- 1.删除流表
DROP TABLE IF EXISTS device_status;
-- 2.创建流表(把 Kafka 实时数据映射为 Flink 可查询的表)
CREATE TABLE device_status (
event_type STRING, -- 事件类型(如状态上报)
device_id STRING, -- 设备编号
status INT, -- 设备状态(1在线/0离线)
temperature DOUBLE, -- 温度
`load` DOUBLE, -- 设备负载(注意:load 是关键字,用反引号)
voltage DOUBLE, -- 电压
event_time STRING, -- 原始时间(字符串格式)
ts AS TO_TIMESTAMP(event_time), -- 计算列:将字符串时间转换为时间类型(窗口统计必须用时间类型)
WATERMARK FOR ts AS ts - INTERVAL '5' SECOND -- 水位线:允许数据最多迟到5秒(解决乱序问题)
) WITH (
'connector' = 'kafka', -- 指定数据来源是 Kafka
'topic' = 'device_status_topic', -- 订阅的 Kafka 主题
'properties.bootstrap.servers' = 'master:9092', -- Kafka 服务器地址
'properties.group.id' = 'rt_device_20260309_01', -- 消费者组ID(控制消费位置)
'scan.startup.mode' = 'latest-offset', -- 从最新数据开始读取
'format' = 'json' -- 数据格式为 JSON
);水位线的作用
如统计:每10秒设备告警数量
统计窗口:10:00:00 ~ 10:00:10
但有条数据:
- 事件时间:10:00:08
- 实际到达时间:10:00:15
如果你允许:等5秒 ,那它还能被算进去
如果超过5秒:就丢弃
🌐 实时窗口(水印)-动画演示
👉 [点击查看](知识拓展/5-1 Flink实时计算窗口讲解.html)
-- 3.查看当前库中的表
SHOW TABLES;
-- 4.查看表结构
DESCRIBE device_status;6.3.4 实时数据写入 Kafka
实验目的:
- Kafka 中的数据是实时产生的流数据,不是一次性文件
- Flink SQL 可以直接从 Kafka Topic 读取数据流,并以表的形式进行查询
- Flink SQL 中的表不是数据库表,而是实时任务的“逻辑视图”
📌 本实验的核心目标不是“计算指标”,而是验证实时数据链路是否打通:
Python → Kafka → Flink SQL
实验步骤:
1.启动Kafka
# 在master/slave1/slave2启动 ZooKeeper
zkServer.sh start
# 在master/slave1/slave2检查 ZooKeeper状态
zkServer.sh status
# 在master/slave1/slave2启动 Kafka
kafka-server-start.sh -daemon /opt/apps/kafka/config/server.properties2.写入状态流数据到 Kafka
# 在master节点中操作【新开窗口】
cd /opt/datas
# 启动设备状态模拟脚本,并将数据写入 Kafka
python 01_device_status_sim.py | \
kafka-console-producer.sh --broker-list master:9092 --topic device_status_topic📌 说明:
01_device_status_sim.py会持续生成设备状态 JSON 数据- 管道符
|表示:左边程序的输出,直接作为右边 Kafka Producer 的输入- 该命令会持续运行,用于不断向 Kafka 写入实时数据
# 另开一个master窗口中操作,检查主题数据
kafka-console-consumer.sh --bootstrap-server master:9092 --topic device_status_topic3.在 Flink SQL 中查询 Kafka 数据
3.1 进入 Flink SQL 客户端
3.2 执行 SQL 查询
在 Flink SQL 客户端中执行以下 SQL 查询,实时查看 Kafka 中的数据:
-- 从 `device_status` 表中实时查询设备 ID、状态、温度和时间戳。
-- 注意:Kafka 源表属于动态表,查询会持续输出数据,需按 Ctrl + C 手动停止
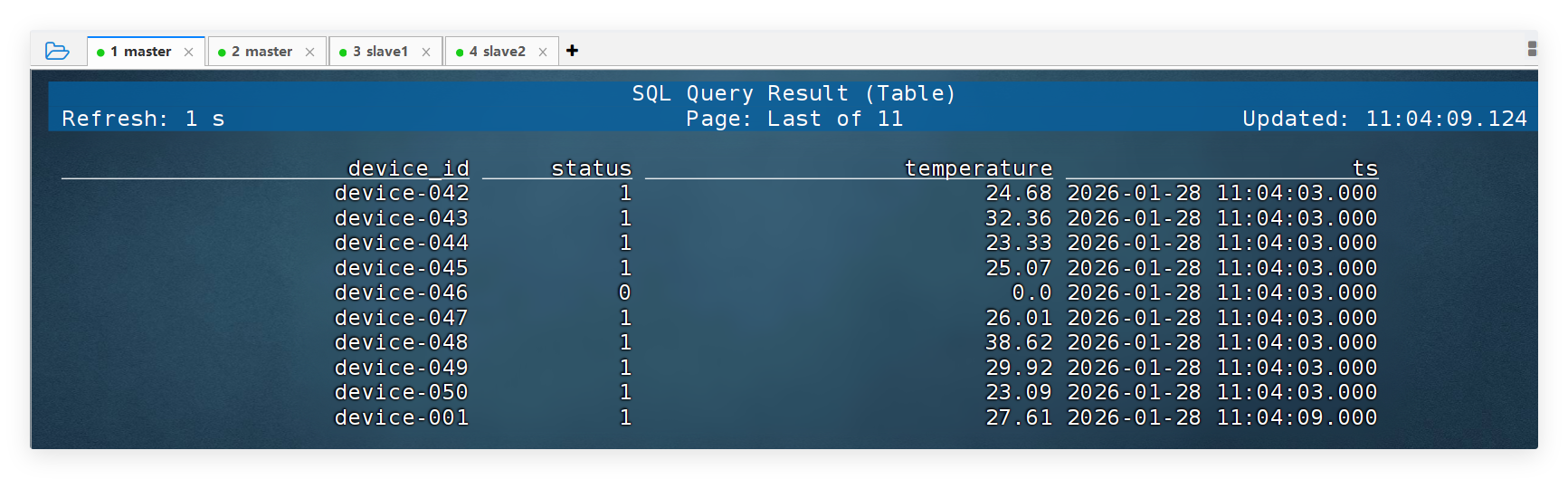
SELECT device_id, status, temperature, ts FROM device_status;📌 现象说明:
- 查询会持续输出数据
- 每产生一条新数据,就会立即显示
- 说明 Flink 已成功从 Kafka 读取实时数据
⚠ 重要说明
1️⃣ 现象说明
当你:
- 关闭
sql-client.sh - 或重启 Flink 集群
再次进入 SQL Client 后,发现:
device_status 表不存在2️⃣ 原因说明(正常现象)
在未使用持久化 Catalog(如 HiveCatalog)时,通过
CREATE TABLE创建的表属于 会话级对象。
其特点:
- 仅在当前 SQL Client 会话中有效
- 关闭会话或重启后会自动消失
- 不会像 Hive / MySQL 那样永久保存
3️⃣ 企业真实做法
在生产环境中,通常不会手动进入 sql-client.sh 建表,而是:
- 将 Flink SQL 写入 Java 程序
- 使用
TableEnvironment.executeSql()启动 - 打包成 Flink 作业 JAR
- 通过
flink run xxx.jar部署运行
👉 只要作业运行,表结构和计算逻辑就持续生效。
6.4 实验
🌐 实时指标讲解-动画演示
👉 [点击查看](知识拓展/5-3 四个实验指标讲解.html)
6.4.1 子实验1:实时在线设备数量统计(10s TUMBLE)
1. 指标说明
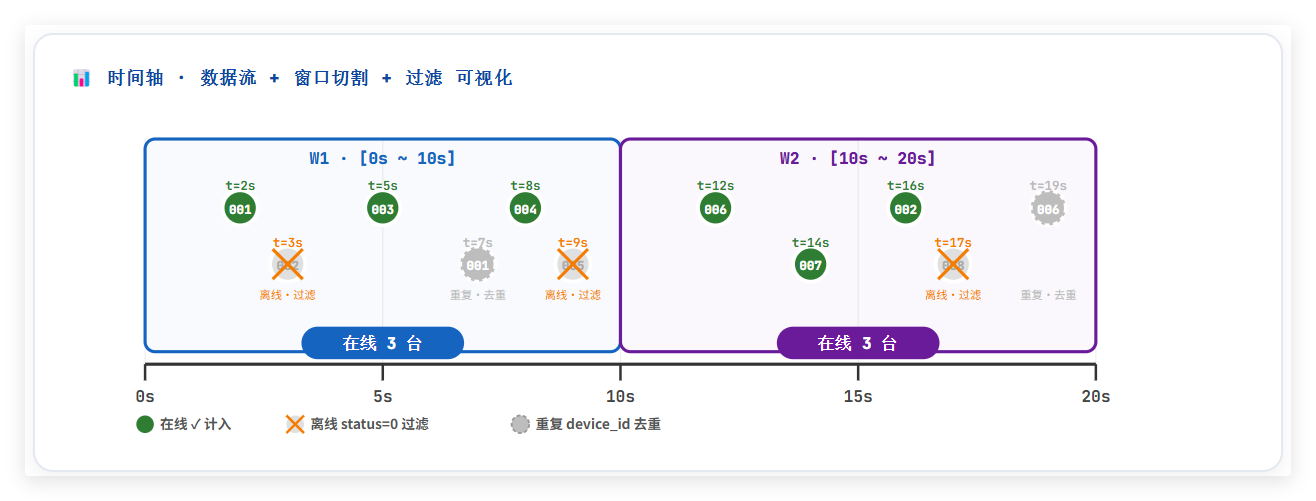
- 任务:每 10 秒统计一次:当前系统中有多少台设备是“在线”的(去重统计)
- 类型:趋势型指标
- 窗口:10 秒窗口
2. Flink SQL

代码逻辑:
数据来源:device_status
时间划分:每10秒一个窗口
条件筛选:只要 status=1
统计方式:按设备编号去重计数
输出结果:窗口结束时间 + 在线设备数
可以先看窗口的样子
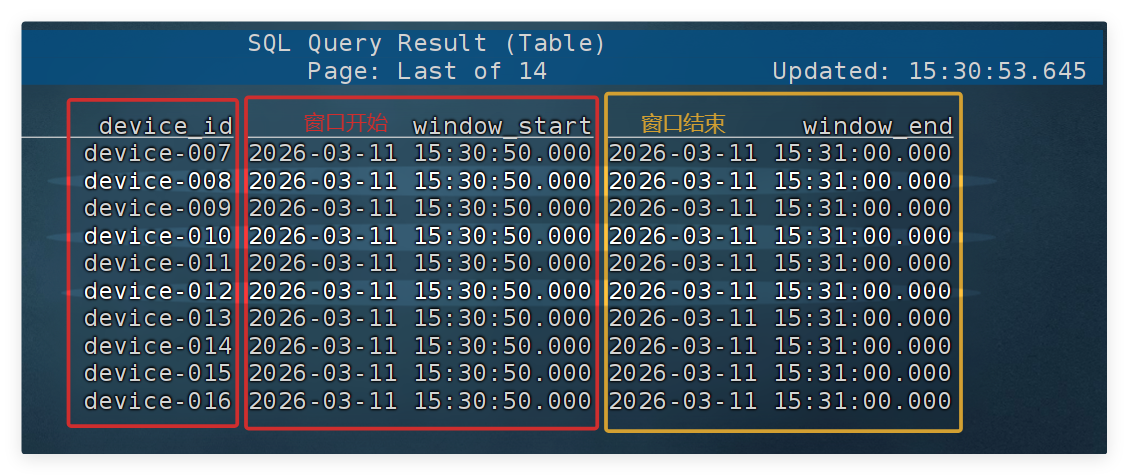
SELECT device_id, window_start, window_end FROM TABLE( TUMBLE( TABLE device_status, DESCRIPTOR(ts), INTERVAL '10' SECOND ) );
SELECT
window_start, -- 窗口开始时间
window_end, -- 窗口结束时间
COUNT(DISTINCT device_id) AS online_count -- 去重统计在线设备数
FROM TABLE(
TUMBLE( -- 窗口函数(滚动窗口,不重叠)
TABLE device_status, -- 数据来源:Kafka 映射的流表
DESCRIPTOR(ts), -- 使用事件时间 ts 定义窗口
INTERVAL '10' SECOND -- 每10秒一个滚动窗口
)
)
WHERE status = 1 -- 只统计在线设备(status=1 表示在线)
GROUP BY window_start, window_end; -- 每个窗口单独统计,window_start / window_end 是窗口函数自动生成的时间字段
TUMBLE是 滚动窗口函数。
一个窗口结束后,才开始下一个窗口,窗口之间不重叠。
window_start和window_end是窗口函数TUMBLE自动生成的。
window_start:窗口开始时间
window_end:窗口结束时间
窗口编号 时间范围(window_start + window_end) 第1个窗口 10:00:00 ~ 10:00:10 第2个窗口 10:00:10 ~ 10:00:20 第3个窗口 10:00:20 ~ 10:00:30 表示 :每个 10 秒窗口,分别统计一次。
运行结果: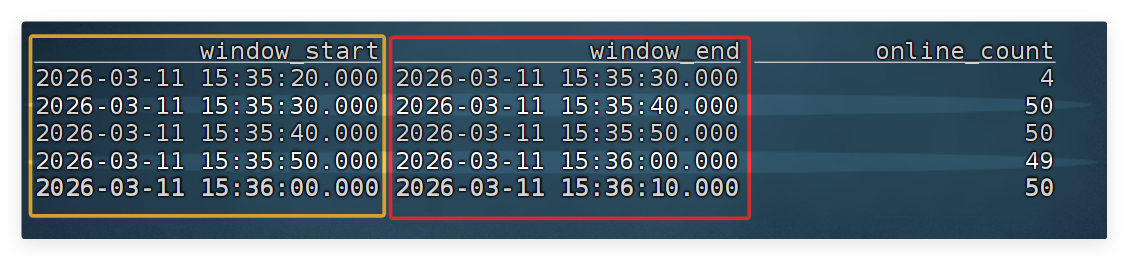
3. 验收
- 每 10 秒输出一条结果
- online_count 数值随设备状态变化
6.4.2 子实验2:实时温度趋势(10s/30s HOP)
1. 指标说明
- 任务:每 10 秒更新一次最近 30 秒内的平均温度和最高温度,用于实时监测设备运行温度变化趋势。
- 类型:趋势型指标
- 窗口:30 秒窗口,每 10 秒滑动一次
2. Flink SQL
-- 每 10 秒更新一次“最近 30 秒”的温度趋势
SELECT
window_start, -- 窗口开始时间
window_end , -- 窗口结束时间
AVG(temperature) AS avg_temp, -- 最近30秒的平均温度
MAX(temperature) AS max_temp -- 最近30秒的最高温度
FROM TABLE(
HOP( -- 窗口函数(滑动窗口)
TABLE device_status, -- 数据来源:Kafka流表
DESCRIPTOR(ts), -- 使用 ts 作为事件时间
INTERVAL '10' SECOND, -- 每10秒滑动一次(更新频率)
INTERVAL '30' SECOND -- 窗口大小30秒(统计范围)
)
)
GROUP BY window_start, window_end; -- 每个滑动窗口单独统计滑动窗口解释:
假设现在时间在 10 点:
10:00:00 ~ 10:00:30 10:00:10 ~ 10:00:40 10:00:20 ~ 10:00:50👉 每10秒向前滑动一次
👉 每次统计最近30秒🌐 实时滑动窗口-动画演示
👉 [点击查看](知识拓展/5-2 滑动窗口讲解.html)
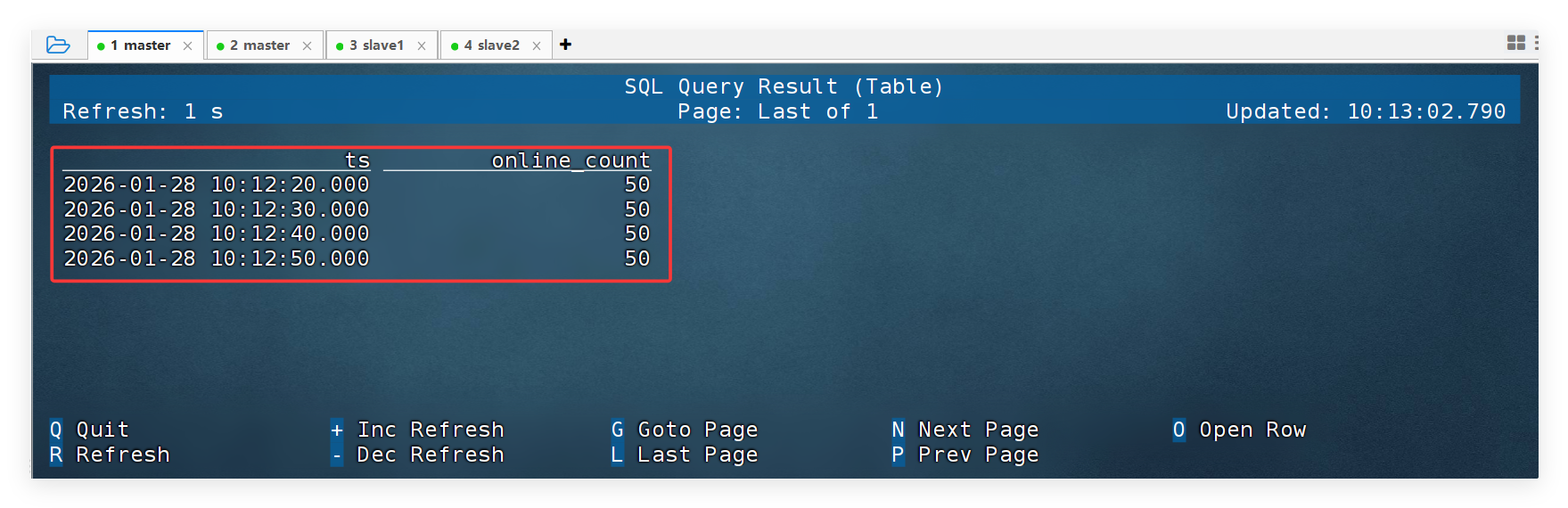
运行结果:
3. 验收
每 10 秒输出一次
温度平滑变化,符合趋势特征

6.4.3 子实验3:实时告警数量统计(10s TUMBLE)
1. 指标说明
- 含义:基于 Flink SQL 从设备状态流中实时识别异常并生成告警事件流,再按 10 秒滚动窗口统计系统告警数量,用于实时监控设备运行风险。
- 类型:规则派生指标
- 窗口:10 秒滚动窗口
- 数据来源:device_status_topic(由状态流推导告警)
2. Flink SQL
第一步:由状态流生成告警事件流视图
在 Flink SQL 中,表用于连接数据源或数据结果,视图仅封装查询逻辑,不连接外部系统、不存储数据。
1.
device_status示例数据(原表)
event_type device_id status temperature load voltage event_time ts device_status device-001 1 82 0.42 219.8 2026-03-09 10:00:01 2026-03-09 10:00:01 device_status device-002 1 27.3 0.58 221.5 2026-03-09 10:00:02 2026-03-09 10:00:02 device_status device-003 1 26.8 0.61 220.7 2026-03-09 10:00:03 2026-03-09 10:00:03 device_status device-004 1 29.1 0.72 198 2026-03-09 10:00:04 2026-03-09 10:00:04 device_status device-005 0 30.4 0.73 218.6 2026-03-09 10:00:05 2026-03-09 10:00:05 device_status device-006 1 28.9 0.92 223.4 2026-03-09 10:00:06 2026-03-09 10:00:06 device_status device-007 1 27.1 0.59 221.2 2026-03-09 10:00:07 2026-03-09 10:00:07 device_status device-008 1 31.5 0.82 224.1 2026-03-09 10:00:08 2026-03-09 10:00:08
- 生成后的视图表
v_alarm_event
device_id alarm_type ts device-001 HIGH_TEMP 2026-03-09 10:00:01 device-004 LOW_VOLT 2026-03-09 10:00:04 device-005 DEVICE_OFFLINE 2026-03-09 10:00:05 device-006 HIGH_LOAD 2026-03-09 10:00:06
-- 查看当前会话中是否已存在视图
SHOW VIEWS;
-- 创建临时视图:告警事件流(只保留异常数据)
CREATE TEMPORARY VIEW v_alarm_event AS
SELECT
device_id, -- 设备编号
CASE -- 根据规则判断告警类型
WHEN temperature >= 80 THEN 'HIGH_TEMP' -- 温度过高
WHEN voltage <= 200 THEN 'LOW_VOLT' -- 电压过低
WHEN `load` >= 0.90 THEN 'HIGH_LOAD' -- 负载过高
WHEN status = 0 THEN 'DEVICE_OFFLINE' -- 设备离线
END AS alarm_type, -- 告警类型字段
ts -- 事件时间(用于后续窗口统计)
FROM device_status -- 数据来源:设备状态流表
WHERE -- 只筛选“异常数据”
temperature >= 80
OR voltage <= 200
OR `load` >= 0.90
OR status = 0;
-- 查看当前会话中是否已存在视图
SHOW VIEWS;
-- 从视图 `v_alarm_event` 中实时查询设备 ID、异常状态和时间戳。
select * from v_alarm_event;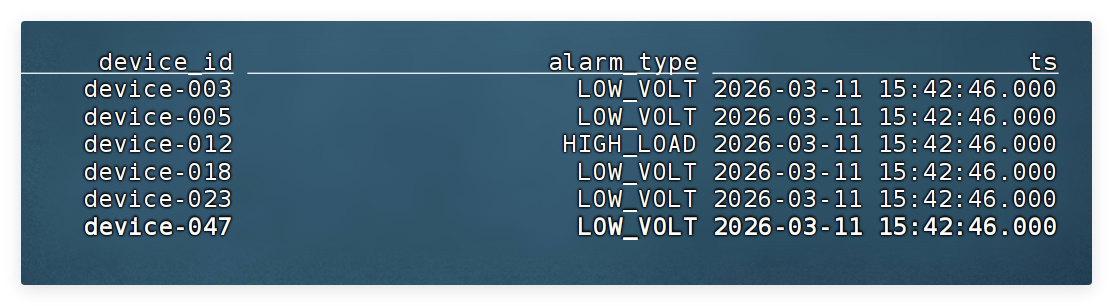
📌 知识重点:
WHERE负责过滤异常CASE负责分类- 只输出真正异常的数据
第二步:统计 10 秒内告警数量
-- 每 10 秒统计一次告警总数量
SELECT
window_start, -- 窗口开始时间
window_end, -- 窗口结束时间
COUNT(*) AS alarm_count -- 该窗口内的告警总次数
FROM TABLE(
TUMBLE(
TABLE v_alarm_event, -- 数据来源:告警事件流(只包含异常记录)
DESCRIPTOR(ts), -- 使用 ts 作为事件时间
INTERVAL '10' SECOND -- 定义 10 秒滚动窗口(不重叠)
)
)
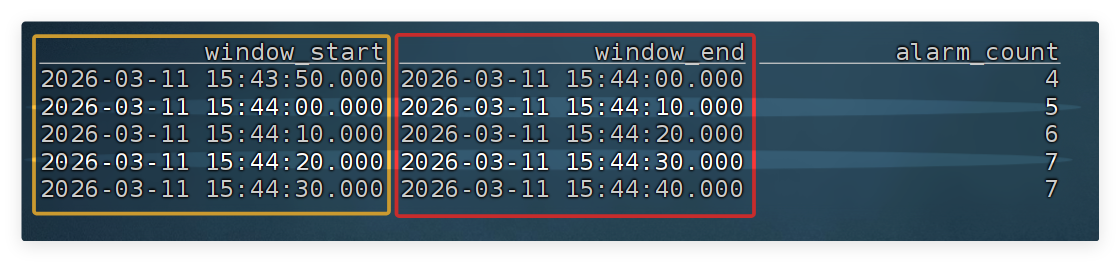
GROUP BY window_start, window_end; -- 每个时间窗口单独统计3. 验收
- 正常运行时可能输出 0(无异常)
- 当温度、电压、负载异常时,数值上升
- 多台设备异常时,数量增加
6.4.4 子实验4:告警 TOP5 设备统计
1. 指标说明
- 含义:每 1 分钟窗口内,告警次数最多的前 5 台设备
- 类型:排行型指标
- 窗口:1 分钟滚动窗口
- 数据来源:
device_status(规则推导得到告警事件流)
2. 分步 SQL
设备数据
↓
找出异常设备(告警事件)
↓
统计每分钟每台设备告警次数
↓
选出告警最多的前5台设备
# 完整数据流
设备数据
↓
Kafka
↓
device_status
↓
v_alarm_event(筛选异常)
↓
alarm_cnt(1分钟窗口统计)
↓
Top5(窗口内排名)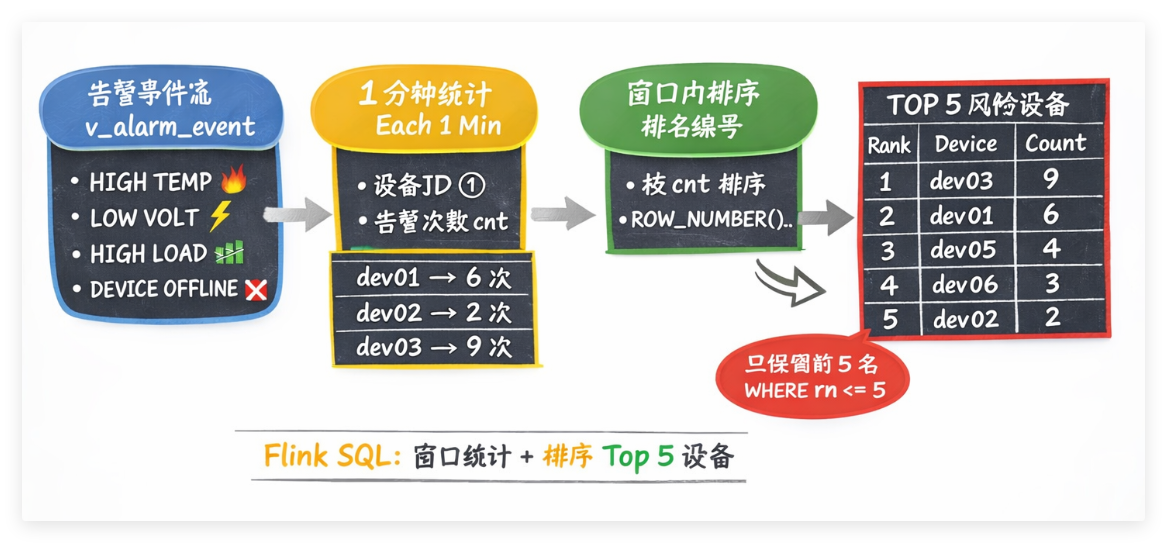
① 先从状态流推导“告警事件流”(只输出异常)
-- 先查询视图是否已存在
SHOW VIEWS;
-- 下面的表之前创建过就不用再创建了
-- 创建临时视图:告警事件流(只保留异常数据)
CREATE TEMPORARY VIEW v_alarm_event AS
SELECT
device_id,
CASE
WHEN temperature >= 80 THEN 'HIGH_TEMP'
WHEN voltage <= 200 THEN 'LOW_VOLT'
WHEN `load` >= 0.90 THEN 'HIGH_LOAD'
WHEN status = 0 THEN 'DEVICE_OFFLINE'
END AS alarm_type,
ts
FROM device_status
WHERE
temperature >= 80
OR voltage <= 200
OR `load` >= 0.90
OR status = 0;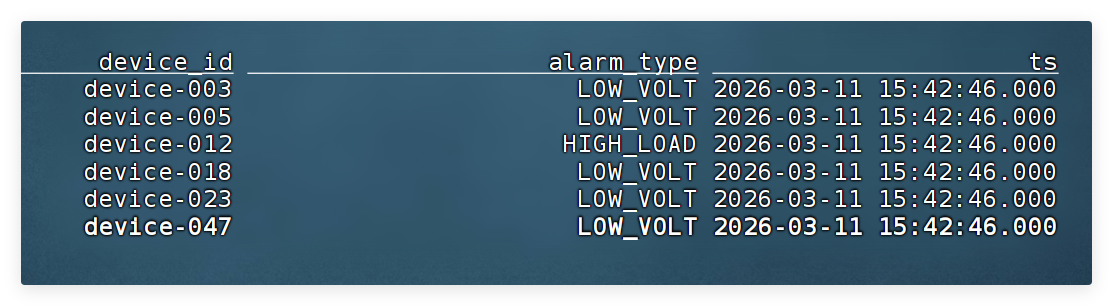
② 先统计每台设备告警次数(1 分钟窗口)
CREATE TEMPORARY VIEW alarm_cnt AS -- 创建临时视图:每分钟各设备告警次数统计结果
SELECT
window_start, -- 窗口开始时间
window_end, -- 窗口结束时间
device_id, -- 设备编号
COUNT(*) AS cnt -- 该设备在窗口内告警次数(计数)
FROM TABLE(
TUMBLE(
TABLE v_alarm_event, -- 数据来源:告警事件流(只包含告警的记录)
DESCRIPTOR(ts), -- 使用 ts 作为事件时间字段来划分窗口
INTERVAL '1' MINUTE -- 定义 1 分钟滚动窗口(不重叠)
)
)
GROUP BY window_start, window_end, device_id; -- 按“窗口 + 设备”分组,每分钟每台设备输出1条统计结果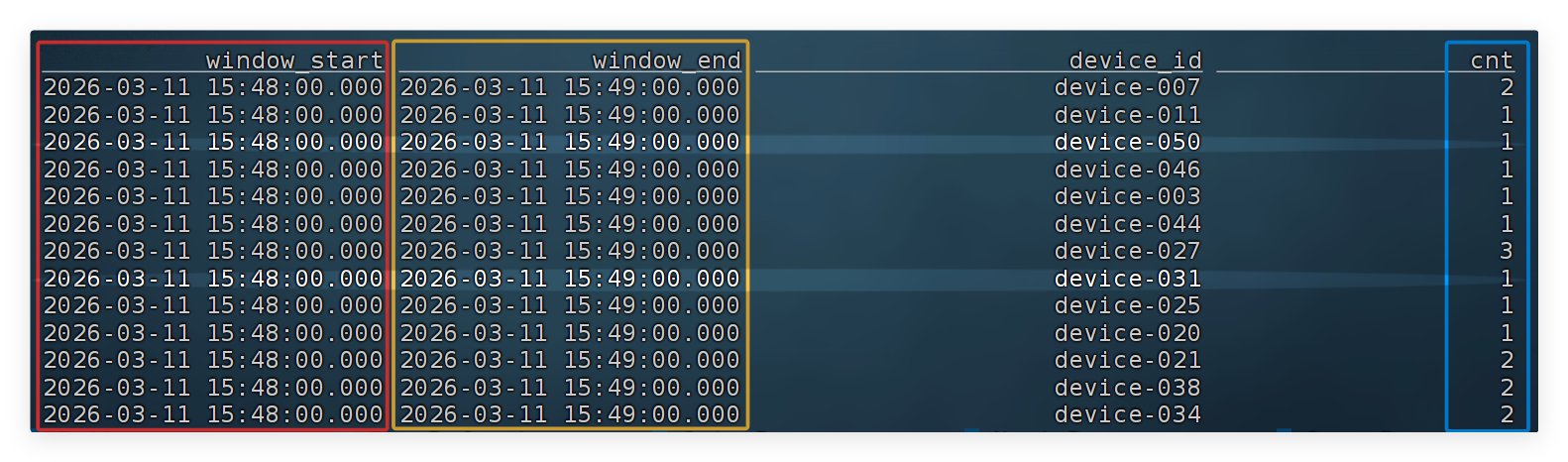
③ 再取 Top5(每个窗口按 cnt 排序)
-- 统计每个时间窗口内 告警次数最多的前 5 台设备
SELECT
CAST(window_end AS DATE) AS dt, -- 提取日期(用于分区或展示)
window_end, -- 窗口结束时间
device_id, -- 设备编号
cnt, -- 该设备在窗口内的告警次数
rn -- 排名
FROM (
SELECT
window_end, -- 每个时间窗口
device_id, -- 设备编号
cnt, -- 该设备的告警次数
ROW_NUMBER() OVER (
PARTITION BY window_end -- 每个窗口单独排名
ORDER BY cnt DESC -- 按告警次数从大到小排序
) AS rn -- 生成排名
FROM alarm_cnt -- 已统计好的“每设备告警次数表”
)
WHERE rn <= 5; -- 只保留前5名(Top5)
ROW_NUMBER() OVER (...) AS rn:在每个窗口内,按照排序结果,从 1 开始给每台设备编号
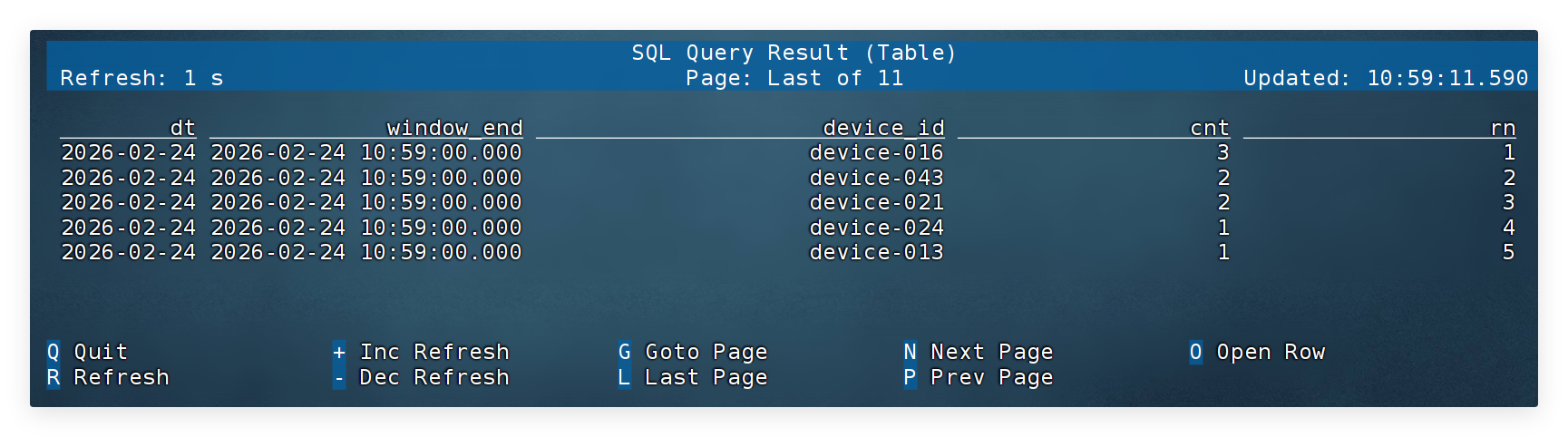
3. 验收
- 每分钟输出 Top5 设备
- 告警多的设备排名靠前