大数据综合实训项目:设备运行状态监控与风险预测可视化大屏
第四章:Kafka 实时数据采集
一、实验背景(应用场景)
在现代企业的生产过程中,数据的实时采集和处理变得越来越重要。企业需要对设备、传感器等设备实时监控,并及时采取措施以防止故障发生。Kafka作为一种高效的分布式消息队列系统,能够实现设备数据的快速传输和流处理。通过将设备数据实时写入Kafka,并将其分流到不同的Topic中,企业能够为后续的实时数据分析、机器学习和数据可视化提供强大的数据支持。
应用场景:
- 企业需要实时监控生产线设备,采集设备数据并实时分析,避免突发故障。
- 实时数据采集为Flink/Spark等数据处理工具提供数据源,帮助企业实时做出决策。

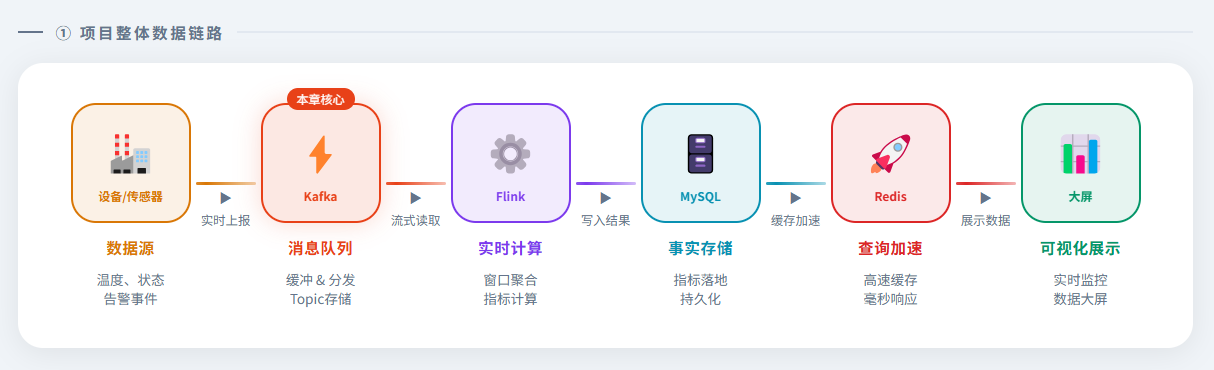
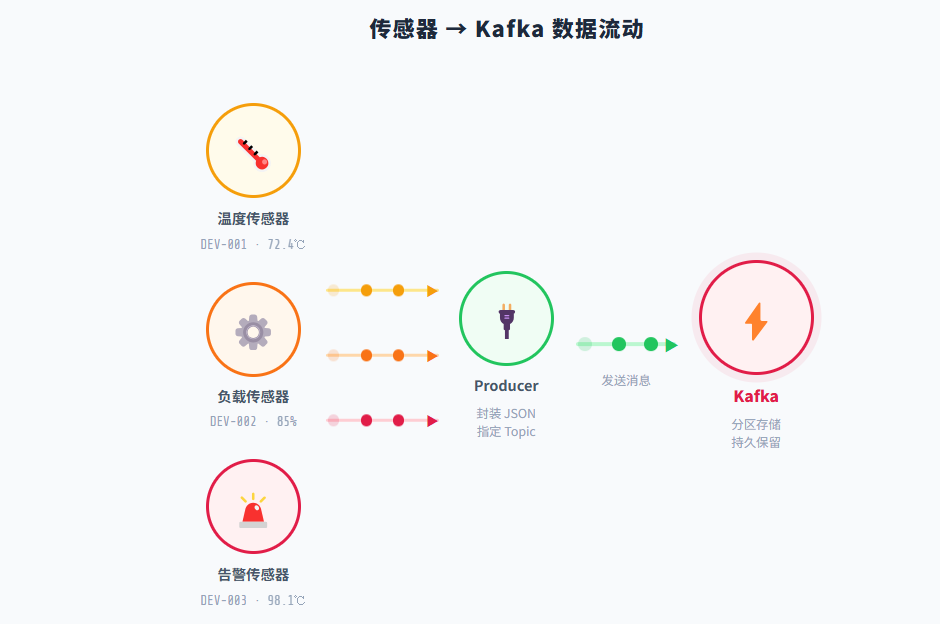
二、实验目标
1. 知识目标
- 理解Kafka的作用,能够将其作为消息队列来传输实时数据。
- 理解Topic在Kafka中的作用,即按业务类型分通道来管理数据流。
2. 能力目标
- 学会创建多个Topic并验证其创建是否成功。
- 掌握使用Python通过标准输出将JSON数据发送到Kafka。
- 使用Kafka官方提供的工具,通过管道方式将数据写入Topic。
- 使用Kafka Consumer实时查看数据流入情况。
3. 素养目标
- 理解字段命名一致性和数据结构稳定性对数据流的影响。
- 培养企业化的实时数据采集思维,为后续的数据处理和机器学习任务(如Flink和ML)铺路。
三、教学重点与难点
1.教学重点
- Topic的作用:如何在Kafka中按不同业务类型创建多个Topic进行数据分流。
- 管道
|的含义:理解如何通过stdout输出数据并通过管道(|)传输给Kafka Producer。 - Kafka Producer/Consumer的基本使用:如何正确地使用Kafka的生产者和消费者工具进行数据读写。
2.教学难点
- 误解告警触发条件:学生可能认为“状态超标就必须立刻产生告警”,但实际上告警是事件触发的,且可能存在冷却时间或概率条件。
- Topic配置错误:Topic名字或地址错误可能导致无法查看数据,学生需要注意正确配置Topic。
四、Kafka 基础
市面上绝大多数物联网传感器的数据,都可以接入到 Kafka。
典型物联网数据链路
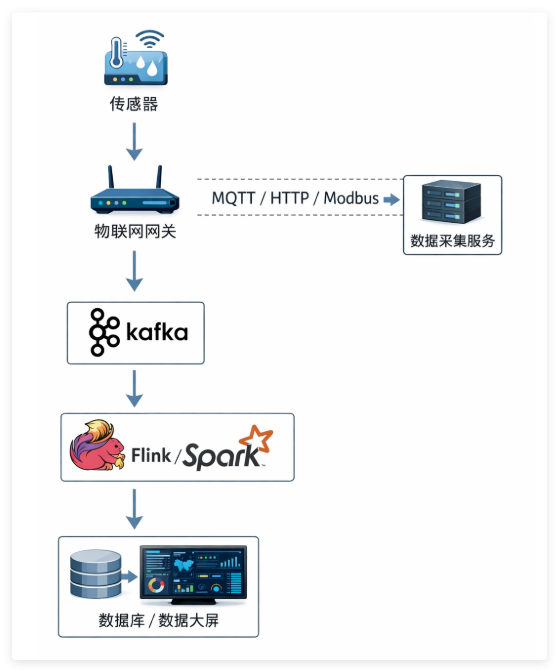
[传感器]
│
▼
[物联网网关] ── (MQTT/HTTP/Modbus) ──▶ [数据采集服务]
│
▼
[Kafka消息队列]
│ 主题:device_status_topic
▼
[Flink / Spark计算引擎]
│
▼
[数据库 / 数据大屏]五、Kafka 主题字段说明表
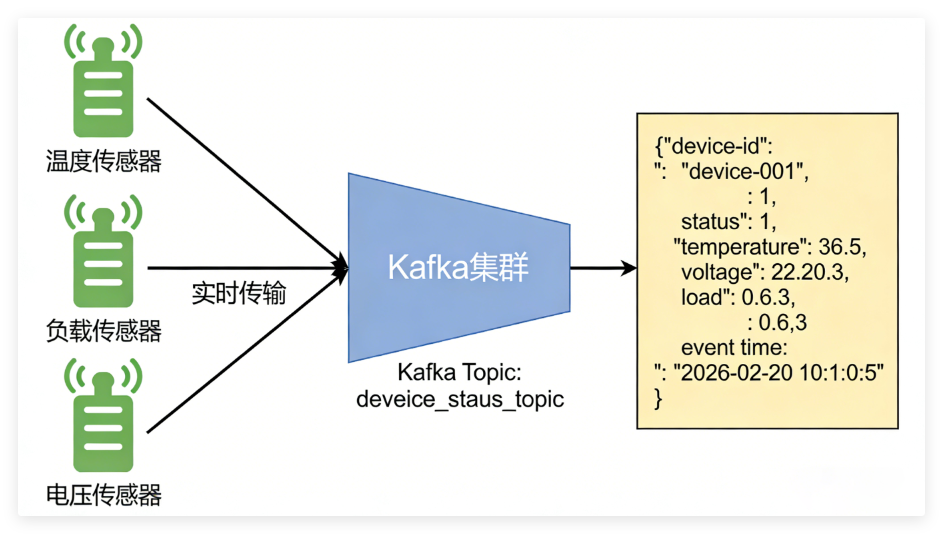
Topic:device_status_topic(设备状态流)
| 英文字段名 | 中文含义 | 类型(建议) | 示例值 |
|---|---|---|---|
| event_type | 事件类型 | string | device_status |
| device_id | 设备编号 | string | device-001 |
| status | 在线状态(1在线/0离线) | int | 1 |
| temperature | 温度(℃) | double | 32.50 |
| load | 负载(0~1) | double | 0.78 |
| voltage | 电压(V) | double | 228.4 |
| event_time | 事件时间 | string | 2026-01-27 10:05:00 |
六、实验:Kafka实时数据采集
启动Kafka
# 在master/slave1/slave2启动 ZooKeeper zkServer.sh start # 在master/slave1/slave2检查 ZooKeeper状态 zkServer.sh status # 在master/slave1/slave2启动 Kafka 服务 kafka-server-start.sh -daemon /opt/apps/kafka/config/server.properties
6.1 创建 Topic
# 在 Kafka 集群中创建名为 device_status_topic 的主题,设置3个分区用于并行处理,副本数为1(单机环境)
kafka-topics.sh --bootstrap-server master:9092 --create \
--topic device_status_topic --partitions 3 --replication-factor 1验证:
# 查看当前 Kafka 集群(master:9092)中已经创建的所有 Topic 列表
kafka-topics.sh --bootstrap-server master:9092 --list6.2 验证实时数据
把下Python 代码文件复制到 master 节点
/opt/datas目录中Python 代码作用:模拟设备实时上报数据,并持续向 Kafka 发送设备状态数据流。
# 在 master 中操作
cd /opt/datas
# 运行脚本,可在屏幕上看到生成的实时数据流
python 01_device_status_sim.py6.3 实时数据写入 Kafka
持续向 Kafka 发送设备状态数据流
python 01_device_status_sim.py | \
kafka-console-producer.sh --broker-list master:9092 --topic device_status_topic📌 教学点
|表示:左边程序的输出,交给右边程序当输入。
6.4 验证实时数据
# 从 device_status_topic 主题中实时消费(查看)Kafka中的设备状态数据流
kafka-console-consumer.sh --bootstrap-server master:9092 --topic device_status_topic七、本章小结
Kafka 解决的是 “数据如何稳定实时进入系统”
本章完成后,Flink 才能做实时统计,Spark/ML 才能做离线分析与预测。
八、承接下一章
下一章进入 Flink 实时处理:
- 从
device_status_topic计算在线数、平均温度、趋势指标 - 为大屏提供实时趋势与告警统计数据
九、Python 实时数据模拟器
作用:模拟产生实时数据流
存放目录:
opt/datas/
运行方式:python xxx.py(只看输出,不直接写 Kafka)数据格式:
{“status”: 1, “load”: 0.51, “event_type”: “device_status”, “event_time”: “2026-02-16 22:04:37”, “voltage”: 216.7, “device_id”: “device-039”, “temperature”: 26.42}
01_device_status_sim.py(状态流:5秒内依次产生50条)
新优化的模拟器
# 01_device_status_sim.py
# -*- coding: utf-8 -*-
import json
import random
import time
import sys
from datetime import datetime
# ========= 可调参数 =========
DEVICE_COUNT = 50 # 设备数量
SEND_INTERVAL_SEC = 5 # 一轮周期(秒):5秒内输出完DEVICE_COUNT条
OFFLINE_PROB = 0.03 # 离线概率
# 温度异常“额外抬升”概率(制造明显高温)
HIGH_TEMP_BIAS_PROB = 0.12 # 原来0.08,略提高:让异常更容易被学到
# 正常分布参数(在线时)
TEMP_BASE = 26
TEMP_STD = 2.5 # 原3,略收窄:正常更集中、异常更突出
LOAD_BASE = 0.65 # 原0.60,略提高:更容易出现高负载边界
LOAD_STD = 0.18 # 原0.15,波动略增:数据更真实
VOLT_BASE = 220
VOLT_STD = 7 # 原6,略增:更真实一点
# ========= 教学阈值(不输出到Kafka,仅用于“造出更像真实的数据”) =========
HIGH_LOAD_BIAS_PROB = 0.10 # 10% 概率制造高负载
VOLT_ABNORMAL_PROB = 0.03 # 3% 概率制造电压异常
# ========================================================================
def now_str():
return datetime.now().strftime("%Y-%m-%d %H:%M:%S")
def clamp(x, lo, hi):
return min(hi, max(lo, x))
def build_msg(device_id, event_time):
# 1) 在线/离线(保持字段不变)
online = 0 if random.random() < OFFLINE_PROB else 1
if online == 1:
# 2) 先生成负载:负载是“驱动温度上升”的关键特征(让特征有关联)
load_raw = random.gauss(LOAD_BASE, LOAD_STD)
# 小概率制造高负载(让后面ML能学到“高负载”模式)
if random.random() < HIGH_LOAD_BIAS_PROB:
load_raw += random.uniform(0.15, 0.35)
load = round(clamp(load_raw, 0.0, 1.0), 2)
# 3) 温度 = 正常温度 + 负载关联项 + (小概率)高温抬升
# 负载越高,温度越高(更符合现实,也更利于随机森林学习)
temp = random.gauss(TEMP_BASE, TEMP_STD) + load * 10.0
# 小概率额外高温(异常更明显)
if random.random() < HIGH_TEMP_BIAS_PROB:
temp += random.uniform(10, 20)
temperature = round(temp, 2)
# 4) 电压:正常围绕220波动,小概率出现明显异常(让voltage也有用)
volt = random.gauss(VOLT_BASE, VOLT_STD)
if random.random() < VOLT_ABNORMAL_PROB:
# 随机制造低压/高压异常(幅度明显,方便教学阈值)
volt += random.choice([-25.0, 25.0])
voltage = round(volt, 1)
else:
# 离线:保持你的原逻辑(不改字段结构)
temperature, load, voltage = 0.0, 0.0, 0.0
# 5) 输出字段完全保持不变(不影响Kafka/Flink/Hive)
return {
"event_type": "device_status",
"device_id": device_id,
"status": online,
"temperature": temperature,
"load": load,
"voltage": voltage,
"event_time": event_time
}
def main():
devices = ["device-%03d" % i for i in range(1, DEVICE_COUNT + 1)]
# 5秒内输出完50条:每条间隔 0.1 秒
interval_per_msg = float(SEND_INTERVAL_SEC) / max(1, DEVICE_COUNT)
while True:
# 同一轮统一时间戳(教学更好理解:一轮采集)
batch_time = now_str()
for d in devices:
msg = build_msg(d, batch_time)
# Python2 写法:保持你原来的风格
print json.dumps(msg, ensure_ascii=False)
sys.stdout.flush()
time.sleep(interval_per_msg)
if __name__ == "__main__":
main()