大数据综合实训项目:设备运行状态监控与风险预测可视化大屏
第三章:数据结构设计与数据仓库建模
一、章节定位说明
- 所属课程:大数据综合实训
- 章节性质:核心基础章(数据认知 + 建模思想 + Hive 实操)
- 本章关键词:
“数据长什么样 → 怎么存 → 怎么准备历史数据 → 后面 Spark/ML 怎么用”
📌 教学说明:
- 本章是后续 Kafka/Flink 实时 与 Spark/ML 离线建模 的共同基础
- 核心目标是让学生理解:
👉 表为什么这样建、历史数据怎么准备、如何支撑后续分析与预测
二、教学目标
1. 知识目标
学生能够:
- 理解 Hive 在项目中的定位(历史明细数据仓库)
- 说清楚 ODS/DWD/DWS 三层的区别与作用
- 理解 状态型数据 与 事件型数据 的区别(为 ML 铺路)
2. 能力目标
学生能够:
- 根据业务需求设计 Hive 核心表
- 在 Hive 中创建 ODS/DWD 表并按分区导入数据
- 理解历史数据与后续 Spark/ML 的关系(特征/标签来源)
3. 素养目标
- 建立规范的数据建模意识
- 理解“数据质量比算法更重要”
- 形成工程化、可维护的数据思维
三、教学重点与难点
教学重点
- Hive 表的业务含义理解
- 数据仓库分层思想(ODS / DWD / DWS)
- 核心业务表之间的关系
教学难点
- 把 Hive 当成普通数据库
- 不理解为什么要分层
- 不清楚“明细数据”和“统计数据”的区别
四、为什么要先做数据结构设计?
引导提问:
❓ 如果没有统一的数据结构,后面会发生什么?
总结:
- 数据混乱:同一个指标多个口径
- 后面 Spark 统计写不出来或写了也不可信
- ML 没法训练(没有历史数据、没有特征维度、没有标签)
📌 强调:
大数据项目,80% 的工作在“设计数据”,不是写代码
五、数据结构总体设计
本项目数据分 3 类、落 3 个存储:
- 原始明细数据(明细层):设备上报的每一条状态数据 → Hive ODS
- 实时指标数据(实时结果层):Flink 计算出的秒级指标 → MySQL RT
- 离线报表与预测结果(报表层):Spark/ML 计算结果 → ClickHouse DWS
大屏查询规则:
- 实时图:查 MySQL(实时指标表)
- 历史/预测图:查 ClickHouse(离线报表与预测结果表)
1. Kafka Topic 数据结构(JSON)
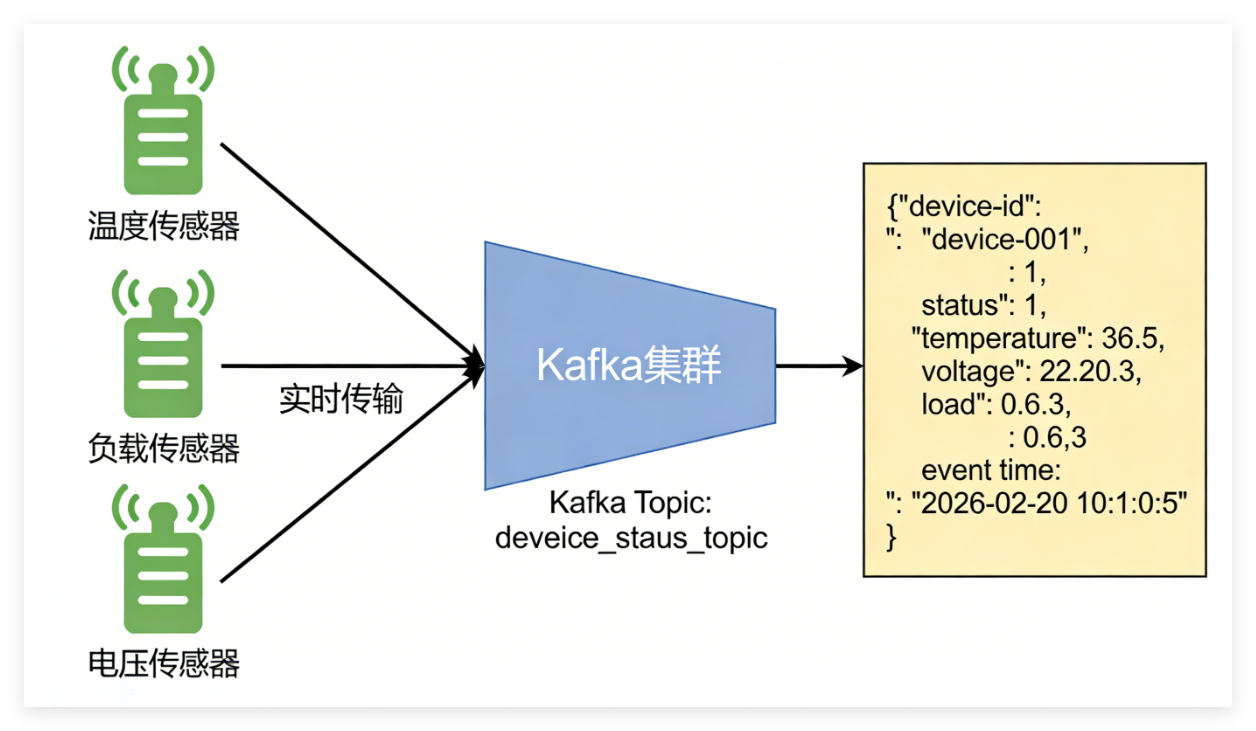
Topic:device_status_topic(设备状态流)
{
"device_id": "device-001",
"status": 1,
"temperature": 36.5,
"voltage": 220.3,
"load": 0.63,
"event_time": "2026-02-20 10:01:05"
}字段说明:
| 字段 | 含义 | 备注 |
|---|---|---|
| device_id | 设备ID | 核心标识 |
| status | 在线状态 | 1在线 / 0离线 |
| temperature | 温度 | 趋势&告警 |
| voltage | 电压 | 异常判断 |
| load | 负载 | 风险特征 |
| event_time | 上报时间 | 字符串时间 |
告警事件不单独 Topic:由 Flink 在状态流里用规则推导(更适合教学,减少复杂度)。
2. Hive 数据仓库表设计(ODS 明细层)
表:iot.ods_device_status_di(按天分区明细表)
用途:长期保存全量明细,供 Spark 离线分析、ML 训练使用。
CREATE TABLE IF NOT EXISTS iot.ods_device_status_di (
device_id STRING COMMENT '设备ID',
status INT COMMENT '在线状态 1在线0离线',
temperature DOUBLE COMMENT '温度',
voltage DOUBLE COMMENT '电压',
load DOUBLE COMMENT '负载',
event_time STRING COMMENT '上报时间字符串',
ts TIMESTAMP COMMENT '解析后的时间戳'
)
PARTITIONED BY (dt STRING COMMENT '分区日期yyyy-MM-dd')
STORED AS ORC;设计要点:
dt分区:按天管理、按天统计更快ts:后续做时间聚合、排序、窗口统计更方便
2. MySQL 实时指标库设计(RT 实时层)
库名建议:rt
MySQL 存的不是“海量明细”,而是 Flink 计算出来的“实时结果”,便于接口查询与大屏刷新。
1)实时在线数(10s 一条)
表:rt_kpi_online_10s
CREATE TABLE rt_kpi_online_10s (
ts DATETIME NOT NULL COMMENT '窗口结束时间/写入时间',
online_count BIGINT NOT NULL COMMENT '在线设备数',
PRIMARY KEY (ts)
);2)实时告警数(10s 一条)
表:rt_kpi_alarm_10s
CREATE TABLE rt_kpi_alarm_10s (
ts DATETIME NOT NULL COMMENT '窗口结束时间/写入时间',
alarm_count BIGINT NOT NULL COMMENT '告警次数',
PRIMARY KEY (ts)
);3)实时温度趋势(10s 一条)
表:rt_temp_trend_10s
CREATE TABLE rt_temp_trend_10s (
ts DATETIME NOT NULL COMMENT '窗口结束时间',
avg_temp DOUBLE NOT NULL COMMENT '平均温度',
max_temp DOUBLE NOT NULL COMMENT '最高温度',
PRIMARY KEY (ts)
);4)告警 Top5(1m 一批)
表:rt_alarm_top5_1m
CREATE TABLE rt_alarm_top5_1m (
window_end DATETIME NOT NULL COMMENT '窗口结束时间',
rn INT NOT NULL COMMENT '排名',
device_id VARCHAR(64) NOT NULL COMMENT '设备ID',
cnt BIGINT NOT NULL COMMENT '告警次数',
PRIMARY KEY (window_end, rn)
);大屏只展示 Top3:直接查
rn <= 3。
3. ClickHouse 报表库设计(DWS 报表层)
库名建议:iot_report
1)历史温度日趋势(Spark 离线生成)
表:dws_temp_trend_day
CREATE TABLE iot_report.dws_temp_trend_day (
dt String,
avg_temp Float64,
max_temp Float64
)
ENGINE = MergeTree
ORDER BY (dt);用途:大屏“近7天历史温度趋势”。
2)预测结果明细(ML 输出)
表:dws_device_pred_detail
CREATE TABLE iot_report.dws_device_pred_detail (
batch_id String COMMENT '预测批次ID(如yyyyMMddHHmm)',
dt String COMMENT '预测日期',
device_id String,
prob1 Float64 COMMENT '高风险概率(0-1)',
risk_level UInt8 COMMENT '风险等级 1低2中3高'
)
ENGINE = MergeTree
ORDER BY (dt, batch_id, device_id);用途:
- 风险等级占比(按
risk_level统计) - 高风险 Top3(按
prob1排序)
六、大屏 6 图与数据表映射(无 Redis)
| 大屏图表 | 数据来源 | 表 | 关键字段 |
|---|---|---|---|
| KPI卡片:在线数 | MySQL | rt_kpi_online_10s | online_count |
| KPI卡片:告警数 | MySQL | rt_kpi_alarm_10s | alarm_count |
| KPI卡片:平均温度 | MySQL | rt_temp_trend_10s | avg_temp |
| KPI卡片:高危数量 | ClickHouse | dws_device_pred_detail | risk_level=3 计数 |
| 实时温度趋势(双折线) | MySQL | rt_temp_trend_10s | ts, avg_temp, max_temp |
| 历史7天温度(柱状) | ClickHouse | dws_temp_trend_day | dt, avg_temp/max_temp |
| 告警Top3(表格) | MySQL | rt_alarm_top5_1m | window_end, rn, device_id, cnt |
| 风险占比(环形) | ClickHouse | dws_device_pred_detail | risk_level 分组 |
| 高风险Top3(表格) | ClickHouse | dws_device_pred_detail | device_id, prob1 |
注:如果您坚持“严格 6 图”,那“告警Top3 + 高风险Top3”可以合并为右下角双表(一个组件两块表)。
七、统一返回结构(接口层建议)
为了让 Vue/ECharts 最省事,建议后端接口返回统一格式:
1)KPI 汇总
{
"online": 87,
"alarm": 5,
"avgTemp": 36.2,
"highRisk": 3
}2)趋势数据
[
{"x":"10:01:00","avg":36.1,"max":39.8},
{"x":"10:01:10","avg":36.3,"max":40.1}
]3)Top榜
[
{"deviceId":"device-007","cnt":9},
{"deviceId":"device-011","cnt":7}
]4)风险占比
[
{"name":"低风险","value":70},
{"name":"中风险","value":20},
{"name":"高风险","value":10}
]八、历史数据模拟方法
1. 为什么需要模拟历史数据?
教师说明:
在真实企业中,设备数据来自长期运行积累。
在教学环境中,我们无法等待真实设备运行 30 天,
因此必须通过模拟历史数据来构建完整分析环境。
如果没有历史数据:
- Spark 无法做离线统计分析
- ClickHouse 没有历史报表数据
- ML 没有训练数据(无法进行随机森林预测)
📌 结论:
模拟历史数据,是构建完整大数据实训环境的必要步骤。
2. 历史数据模拟思路
本教程只模拟一个核心原始表:ods_device_status_di(设备运行明细表)
说明:
- 实时指标不需要手工模拟(由 Flink 自动生成)
- 离线分析和预测必须依赖原始明细数据
3. 历史数据模拟规则
(1)ods_device_status_di 模拟规则(状态型数据)
为了兼顾教学可操作性与数据真实性,建议如下规则:
| 项目 | 建议范围 |
|---|---|
| 设备数量 | 10~20 台(教学先小规模) |
| 时间跨度 | 30 天 |
| 采样频率 | 每分钟 1 条 |
| 数据规模估算 | 20台 × 60 × 24 × 30 ≈ 864000 条 |
字段取值建议
| 字段 | 模拟范围 | 说明 |
|---|---|---|
| temperature | 20~45℃ | 少量生成 ≥80℃ 用于触发告警 |
| load | 0.20~0.95 | 模拟设备负载波动 |
| voltage | 210~240 | 正常电压范围 |
| status | 绝大多数为1 | 少量为0模拟掉线 |
说明:
- 温度偶尔生成异常值,用于测试告警规则
- status 偶尔为 0,用于测试在线率指标
4. CSV 文件示例(字段与 ODS 表结构一致)
device_status.csv 示例(单行)
device-001,1,26.5,228.6,0.42,2026-01-20 10:00:00字段顺序对应:
device_id,status,temperature,voltage,load,event_time📌 注意:
CSV 字段顺序必须与 Hive 表字段顺序一致。
5. 数据导入 Hive(示例)
假设导入 2026-01-20 当天数据:
LOAD DATA LOCAL INPATH '/data/device_status_2026-01-20.csv'
INTO TABLE iot.ods_device_status_di
PARTITION (dt='2026-01-20');十、本章小结
通过本章学习,我们完成了:
- 明确 Hive 在项目中的定位:历史档案库
- 完成 ODS/DWD 的核心表建模
- 设计并准备了可支撑 Spark/ML 的历史数据(特征 + 标签)
📌 一句话总结(可板书):
第三章解决:数据怎么设计、怎么存、怎么准备好。
十一、承接下一章
下一章进入 Kafka 实时数据采集,
让数据不再只是历史文件,而是实时流动进入系统。
十二、历史数据生成脚本(Python 版 )
1. 模拟目标
- 让 Hive 里有足够的历史明细数据支撑 Spark 离线分析
- 同时构造有规律的告警事件,让随机森林能学到“风险规律”,而不是纯随机
2. 标准版数据规模
| 项目 | 参数 |
|---|---|
| 设备数量 | 50 台(device-001 ~ device-050) |
| 历史天数 | 7 天 |
| 采样频率 | 每 1 分钟 1 条/设备 |
device_status 行数 |
50 × 1440 × 7 = 504,000 行(约 50 万) |
| 分区策略 | Hive 按天分区:dt=YYYY-MM-DD |
说明:50万行对 Hive/Spark 来说很轻松,但足够“企业化”。
3. device_status(状态表)模拟规则(多特征,支撑 ML)
3.1 字段范围
| 字段 | 规则/范围 | 说明 |
|---|---|---|
| status | 1 为主,0 少量 | 掉线率控制在 1%~3% |
| temperature | 20~45℃ | 正常 22 |
| load | 0.20~0.95 | 大多数 0.3~0.7;高负载 0.85+ |
| voltage | 210~240V | 正常 220~235;异常时波动更大 |
3.2 让数据“更像真实”的规律
- 同一设备温度是连续变化(不是每分钟乱跳):
用“上一分钟温度 + 小幅波动”生成 - 高负载时温度更容易升高:
load 越高,temperature 上升趋势越明显 - 掉线时可设置:status=0,temperature/load/voltage 可置为 0 或保持上一次(两种都可以,教学建议置 0 更直观)
4. ML 正负样本比例控制
预测目标是:
未来 10 分钟内是否发生告警(0/1)
为了让随机森林有效,建议:
- 正样本比例(label=1)控制在:5%~15%
如何保证?
不要把阈值设太低(否则告警太多)
不要让告警完全随机(否则学不到规律)
用上面的概率规则 + 冷却时间,就能把比例稳定压在合理区间
同一设备温度是连续变化(不是每分钟乱跳):
用“上一分钟温度 + 小幅波动”生成高负载时温度更容易升高:
load 越高,temperature 上升趋势越明显掉线时可设置:status=0,temperature/load/voltage 可置为 0 或保持上一次(两种都可以,教学建议置 0 更直观)
5.脚本说明
用于模拟企业设备的历史运行数据(批量数据)
默认生成两类数据文件:
device_status_YYYY_MM.csv(设备运行状态明细,业务表)device_status_with_label_YYYY_MM.csv(机器学习训练数据,比上面的表多一列Lable,表示“异常/正常”)
数据字段顺序与 Kafka 实时流 完全一致:
event_type, device_id, status, temperature, load, voltage, event_time生成的随机数据具备以下特点:
- 温度与负载存在关联关系
- 少量高温 / 高负载 / 电压异常
- 离线数据独立可识别
- 异常样本比例适合随机森林训练
支撑后续完整数据链路:
- Hive 外部表导入
- Spark 离线统计分析
- ML(随机森林)模型训练
- ClickHouse 数据仓库查询
- 可视化大屏展示
7.完整 Python 脚本
# =============================== # 生成机器学习标签(label) # =============================== # 规则说明: # 只要设备出现“任意一种异常情况”,就认为该条数据是异常(label=1) # 否则认为是正常(label=0) if ( status == 0 # ① 设备离线(最严重异常) or temperature >= 40 # ② 温度过高(高温风险) or load >= 0.85 # ③ 负载过高(运行压力过大) or voltage <= 205 # ④ 电压过低(低压异常) or voltage >= 235 # ⑤ 电压过高(高压异常) ): label = 1 # 标记为异常 else: label = 0 # 标记为正常只要设备“任何一个指标不正常”,label 就是 1。总结如下:
1️⃣ status == 0
设备离线,一定异常。
2️⃣ temperature >= 40
温度过高,存在过热风险。
3️⃣ load >= 0.85
负载接近满载,设备压力大。
4️⃣ voltage <= 205 或 >= 235
电压偏离正常范围(220V ± 15V)。
"""
第三章:Hive 历史数据模拟脚本
默认生成两个文件:
1)device_status_YYYY_MM.csv —— 业务表(导入 Hive),不带Lable标签列
2)device_status_with_label_YYYY_MM.csv —— ML 训练用数据,带Lable标签列
字段顺序:
event_type, device_id, status, temperature, load, voltage, event_time
"""
import random
import csv
from datetime import datetime, timedelta
import os
# =========================
# 参数
# =========================
EVENT_TYPE_VALUE = "device_status"
DEVICE_COUNT = 50
DAYS = 30
INTERVAL_MINUTES = 1
START_DATE = "2026-01-01"
OFFLINE_PROB = 0.03
HIGH_TEMP_BIAS_PROB = 0.12
HIGH_LOAD_BIAS_PROB = 0.10
VOLT_ABNORMAL_PROB = 0.03
TEMP_BASE = 26
TEMP_STD = 2.5
LOAD_BASE = 0.65
LOAD_STD = 0.18
VOLT_BASE = 220
VOLT_STD = 7
HIGH_TEMP = 40
HIGH_LOAD = 0.85
LOW_VOLT = 205
HIGH_VOLT = 235
OUTPUT_DIR = "./output"
os.makedirs(OUTPUT_DIR, exist_ok=True)
def clamp(x, lo, hi):
return min(hi, max(lo, x))
def is_abnormal(status, temperature, load, voltage):
if status == 0:
return True
if temperature >= HIGH_TEMP:
return True
if load >= HIGH_LOAD:
return True
if voltage <= LOW_VOLT or voltage >= HIGH_VOLT:
return True
return False
def generate_data():
start_time = datetime.strptime(START_DATE, "%Y-%m-%d")
total_steps = int((DAYS * 24 * 60) / INTERVAL_MINUTES)
month_tag = start_time.strftime("%Y_%m")
status_file = f"{OUTPUT_DIR}/device_status_{month_tag}.csv"
label_file = f"{OUTPUT_DIR}/device_status_with_label_{month_tag}.csv"
devices = [f"device-{i:03d}" for i in range(1, DEVICE_COUNT + 1)]
status_rows = []
label_rows = []
for step in range(total_steps):
current_time = start_time + timedelta(minutes=step * INTERVAL_MINUTES)
ts_str = current_time.strftime("%Y-%m-%d %H:%M:%S")
for device in devices:
status = 0 if random.random() < OFFLINE_PROB else 1
if status == 1:
load_raw = random.gauss(LOAD_BASE, LOAD_STD)
if random.random() < HIGH_LOAD_BIAS_PROB:
load_raw += random.uniform(0.15, 0.35)
load = round(clamp(load_raw, 0.0, 1.0), 2)
temp = random.gauss(TEMP_BASE, TEMP_STD) + load * 10.0
if random.random() < HIGH_TEMP_BIAS_PROB:
temp += random.uniform(10, 20)
temperature = round(temp, 2)
volt = random.gauss(VOLT_BASE, VOLT_STD)
if random.random() < VOLT_ABNORMAL_PROB:
volt += random.choice([-25.0, 25.0])
voltage = round(volt, 1)
else:
temperature, load, voltage = 0.0, 0.0, 0.0
row = [
EVENT_TYPE_VALUE,
device,
status,
temperature,
load,
voltage,
ts_str
]
status_rows.append(row)
label = 1 if is_abnormal(status, temperature, load, voltage) else 0
label_rows.append(row + [label])
# 写业务表
with open(status_file, "w", newline="", encoding="utf-8") as f:
writer = csv.writer(f)
writer.writerow([
"event_type", "device_id", "status",
"temperature", "load", "voltage", "event_time"
])
writer.writerows(status_rows)
# 写训练表
with open(label_file, "w", newline="", encoding="utf-8") as f:
writer = csv.writer(f)
writer.writerow([
"event_type", "device_id", "status",
"temperature", "load", "voltage", "event_time", "label"
])
writer.writerows(label_rows)
print("✅ 两个文件已生成")
print(f"📄 业务数据:{len(status_rows)} 条")
print(f"📄 训练数据:{len(label_rows)} 条")
# 直接运行
generate_data()