日志采集工具Flume的部署
一. Flume概述与核心架构
1.1 什么是 Flume(概述)
✅ Flume 是干什么的?
Flume 是 Apache 提供的一个分布式日志采集系统。
它就像“数据搬运工”,负责把分布在不同服务器上的日志文件、监控数据或消息流,稳定、高效地传送到大数据存储系统中,比如:
HDFS(分布式文件系统)
Kafka(消息队列)
HBase(数据库)
👉 一句话:Flume 用来采集、传输数据流
✅ Flume 能接收哪些数据?
Flume 能接收多种数据来源(Source),包括:
系统日志文件
Kafka 消息
Socket 端口发来的数据
自定义日志目录等
在 Flume 里,这些数据来源叫做 Source(源头)。
✅ Flume 怎么传输数据?
Flume 的核心设计是一个 流式传输通道:
Source(数据源)→ Channel(中转站)→ Sink(目的地)
Source:负责接收外部数据Channel:负责临时存放数据(像个缓冲区)Sink:负责把数据写到目标系统(比如 HDFS、Kafka)
1.2 Flume 的基本结构和组件
✅ Flume 的核心单位是:Agent
Agent 是 Flume 的最小运行单元。
一个 Agent 就是一台运行中的 Flume 实例,作用就像一个“采集和传输工人”,负责把数据从源头送到目的地。
每个 Agent 由三大核心组件构成:
Source(源头) + Channel(中转站) + Sink(目的地)
🟡 1. Source(数据源)
负责从外部接收数据,比如文件、端口、Kafka等。
Source 可以监听文件、端口、Kafka 等多种来源;
每接收到一条数据,Flume 会把它封装成一个 事件(Event);
然后发送到下一个环节 —— Channel。
🟡 2. Channel(数据中转站)
是
Source和Sink之间的桥梁。
接收来自 Source 的事件;
临时缓存数据;
等待 Sink 来取走。
常见的三种 Channel:
| 类型 | 特点 | 使用场景 |
|---|---|---|
| Memory Channel | 存在内存中,速度快但易丢失数据 | 小数据、测试环境 |
| File Channel | 存磁盘上,安全但速度较慢 | 正式环境 |
| Kafka Channel | 直接接 Kafka | Flume 与 Kafka 联合使用 |
🟡 3. Sink(数据输出)
从
Channel里拿数据,发到最终目的地。
比如:
存到 HDFS 文件系统
发到 HBase 表
写入 Kafka 主题
或推送给其他系统
✅ 总结
Flume 是一个把日志 “采进来,再送出去” 的工具,由 Source(进)→ Channel(存)→ Sink(出) 三部分组成,像一个可定制的“数据输送带”。
1.3 系统特性
分布式设计:
Flume由多个Agent组成,每个Agent独立运行、负责不同的数据采集或传输任务。这些 Agent 之间可以相互连接,形成一个 分布式的数据采集系统,实现数据从各处高效汇聚到中心存储。数据传递与管理:每个
agent在内部包含Source、Channel和Sink三个核心组件,共同负责数据的传递和管理。
event /ɪˈvent/ 事件 sink /sɪŋk/ 下沉 channel /ˈtʃænl/ 渠道,传输 Agent /ˈeɪdʒənt/ 代理

主要作用:
实时读取服务器本地磁盘或指定端口的数据,将数据写入到HDFS或者kafka。

1.4 Flume Event的概念
Event = Flume 中传输的“数据包”
Flume 中的数据,都是以 Event 的形式在 Source → Channel → Sink 之间传来传去的。

Event 的结构是什么?
每条 Event 都有两部分:
| 部分 | 含义 | 举例 |
|---|---|---|
| Header | 头部,元数据 | 时间戳、来源、事件类型、用户ID |
| Body | 内容,实际数据 | 日志正文、用户行为、商品信息 |
✅ 举个通俗易懂的例子
假设你采集的是一条电商日志,它会变成这样一条 Event:
Header:
timestamp: 2024-11-11 14:20:00
source: 京东商城
type: 购买事件
user_id: user456
order_id: order789
Body:
用户购买商品:"iPhone 15", 数量: 1, 价格: ¥6999你看:Header 是背景信息,Body 是具体行为。
✅ Flume 中 Agent 和 Event 的关系是?
通俗地讲,Flume中的Agent和Event之间的关系可以理解为传输与处理的关系。Event是Agent中用于传输、处理的基本数据单位,而Agent则负责控制Event的传输与处理过程。
在 Flume 中,Event 是最小的数据单位,它在各个组件中传输,而 Agent 就是负责搬运这些 Event 的“数据工人”。
1.5 Flume采集系统结构图
1.简单结构
单个agent采集数据
Flume系统的核心角色是agent,它是一个Java进程,通常运行在日志收集节点上,以事件的形式将数据从源头传输到目的地

2. 复杂结构
多级Agent之间串联

✅ 使用场景举例:
假设你是某大型电商公司:
🏢 北京、上海、广州 各部署一台 Web 服务器
每台服务器都有很多访问日志和用户行为数据
你希望把这些数据统一存进 HDFS,做后续分析,比如用户画像、推荐系统
📌 你就可以部署以下结构:
| 地区 | 部署内容 |
|---|---|
| 北京 | Agent1 采集日志 |
| 上海 | Agent2 采集日志 |
| 广州 | Agent3 采集日志 |
| 数据中心 | Agent4 汇总 + 写入 HDFS |
这样做的好处是:
分区域采集,不影响彼此运行
日志集中汇总,便于分析建模
系统结构清晰,易于扩展和维护
二.flume的部署
2.1 伪分布环境-安装flume
伪分布式环境指的是在一台机器上模拟多台机器的分布式环境,用于学习和测试分布式系统。
跳过此步骤
2.2 集群环境-安装flume
2.2.1 环境准备
Hadoop集群(三台主机master,slave1,slave2)
Flume下载地址: flume下载官网
2.2.2 解压安装包
上传apache-flume-1.9.0-bin.tar.gz在master上的/opt/software文件夹下
# 解压
cd /opt/software
tar -zxvf apache-flume-1.9.0-bin.tar.gz -C /opt/apps
# 改名
cd /opt/apps
mv ./apache-flume-1.9.0-bin ./flume #将解压的文件修改名字为flume,简化操作2.2.3 配置环境变量
# 在master上打开环境变量
vi /etc/profile
# 添加以下内容
# Flume 安装路径
export FLUME_HOME=/opt/apps/flume
export PATH=$PATH:$FLUME_HOME/bin
# export FLUME_CONF_DIR=$FLUME_HOME/conf
# 分发环境变量文件到 slave1 和 slave2 主机
scp -r /etc/profile slave1:/etc
scp -r /etc/profile slave2:/etc
# 分别在master/slave1/slave2主机运行下面的命令,使环境变量生效:
source /etc/profile
# 分别在master/slave1/slave2节点查看环境变量的路径
echo $PATH2.2.4 配置flume-env.sh环境变量
cd /opt/apps/flume/conf
# 复制文件
cp ./flume-env.sh.template ./flume-env.sh
# 编辑文件
vi ./flume-env.sh
# 添加以下内容
export JAVA_HOME=/opt/apps/jdk2.2.5 解决Flume 和 Hadoop 使用的 Guava库版本不一致而导致的冲突
Guava 是 Java 项目中广泛使用的实用工具包,它的各个模块都旨在提升开发效率和代码可读性。
Flume 自带的是 较低版本的 Guava(如 11.0.2);
而 Hadoop(尤其是 3.x 版本)使用的是 更高版本的 Guava(如 27.x);
通过手动替换 Flume 中的 Guava 版本,使其与 Hadoop 保持一致,避免类冲突和运行异常。
# 解决方案:把高版本替代低版本
# 修改guava文件名,使之失效
mv /opt/apps/flume/lib/guava-11.0.2.jar /opt/apps/flume/lib/guava-11.0.2.jar.bf
# 复制hadoop下的高版本guava库到Flume中
cp /opt/apps/hadoop/share/hadoop/common/lib/guava-27.0-jre.jar /opt/apps/flume/lib/2.2.6 查看flume版本信息
# 查看flume版本信息
flume-ng version
# 运行结果
Flume 1.7.0
Source code repository: https://git-wip-us.apache.org/repos/asf/flume.git
Revision: 511d868555dd4d16e6ce4fedc72c2d1454546707
Compiled by bessbd on Wed Oct 12 20:51:10 CEST 2016
From source with checksum 0d21b3ffdc55a07e1d08875872c00523常见报错:在运行上面的命令查询版本时报下图的错误
问题描述: 如果系统已经安装了 HBase,且 HBase 的
hbase-env.sh中设置了HBASE_CLASSPATH,该路径中包含了 HBase 所依赖的 jar 包,可能会与 Flume 自身的 classpath 冲突,导致 Flume 无法正确找到自己的类。解决方法:
依次在
Master/slave1/slave2三个节点进行如下操作!# 修改hbase-env.sh配置文件
cd /opt/apps/hbase/conf
vi hbase-env.sh更改如下:
# 修改 HBASE_CLASSPATH 配置
export HBASE_CLASSPATH_PREFIX=/opt/apps/hadoop/etc/hadoop这样配置后:
只将 Hadoop 配置目录添加到 HBase 的 classpath 前缀中;
避免 HBase 启动时将一大堆 jar 包(可能含有和 Flume 冲突的类)注入系统 classpath;
不会干扰 Flume 的正常运行。

2.2.7 创建日志文件目录和检查点目录
# 创建日志目录,供 Flume 输出运行日志
mkdir -p /opt/apps/flume/logs
# 创建 File Channel 使用的检查点目录
mkdir -p /opt/apps/flume/data/flume/checkpoint解释:
1.日志文件目录:
Flume 日志通常输出到
$FLUME_HOME/logs目录,建议提前创建并保持清空,确保日志系统能正常启动和输出日志。2.检查点目录
checkpoint的作用:
这个目录是 Flume 的 File Channel 的检查点目录,用于在 Flume 出现异常停止或系统宕机时恢复数据。
2.2.8 分发Flume到slave各节点
把在master节点配置好的flume分发到slave1/slave2各节点上
scp -r /opt/apps/flume/ slave1:/opt/apps/
scp -r /opt/apps/flume/ slave2:/opt/apps/至此,安装flume(集群模式)完成
三、实验
配置环境:
确保 Hadoop集群能正常运行。
确保 Flume 集群能正常运行。
启动Hadoop
# 在master启动HDFS
start-dfs.sh
# 在slave1启动YARN
start-yarn.sh实验3:Flume收集并传输日志数据到 HDFS
【实验任务】设置并运行 Flume 以收集并传输日志数据到 HDFS
【实验目标】本实验旨在使用 Flume 配置文件来收集系统日志文件,并将其实时传输到 Hadoop 分布式文件系统(HDFS)。实验将涉及配置 Flume agent、source、sink 和 channel。
【实验步骤】
1.编辑 Flume 配置文件
在master的/opt/apps/flume/conf 中创建配置文件,命名为 test3_log_hdfs.conf
cd /opt/apps/flume/conf
# 创建空文件
touch test3_log_hdfs.conf双击打开编辑,使用以下配置内容:

2.创建日志文件(准备 source 输入)
在启动 Flume Agent 前,必须确保 Source 中要读取的日志文件已存在,否则 Flume 启动时会因找不到文件而报错。
# 在 master 上创建日志目录(如果尚未存在)
mkdir -p /opt/apps/flume/data
# 创建一个空日志文件供 tail -F 使用
touch /opt/apps/flume/data/logfile.log3.启动 Flume Agent:

4.模拟实时日志,输入文本验证
# 在slave1上运行下面的命令添加文本,模拟实时日志
# 通过SSH连接到 master 服务器,并将输入的数据追加写入到logfile.log文件中
ssh master "cat >> /opt/apps/flume/data/logfile.log"5.验证和监控:
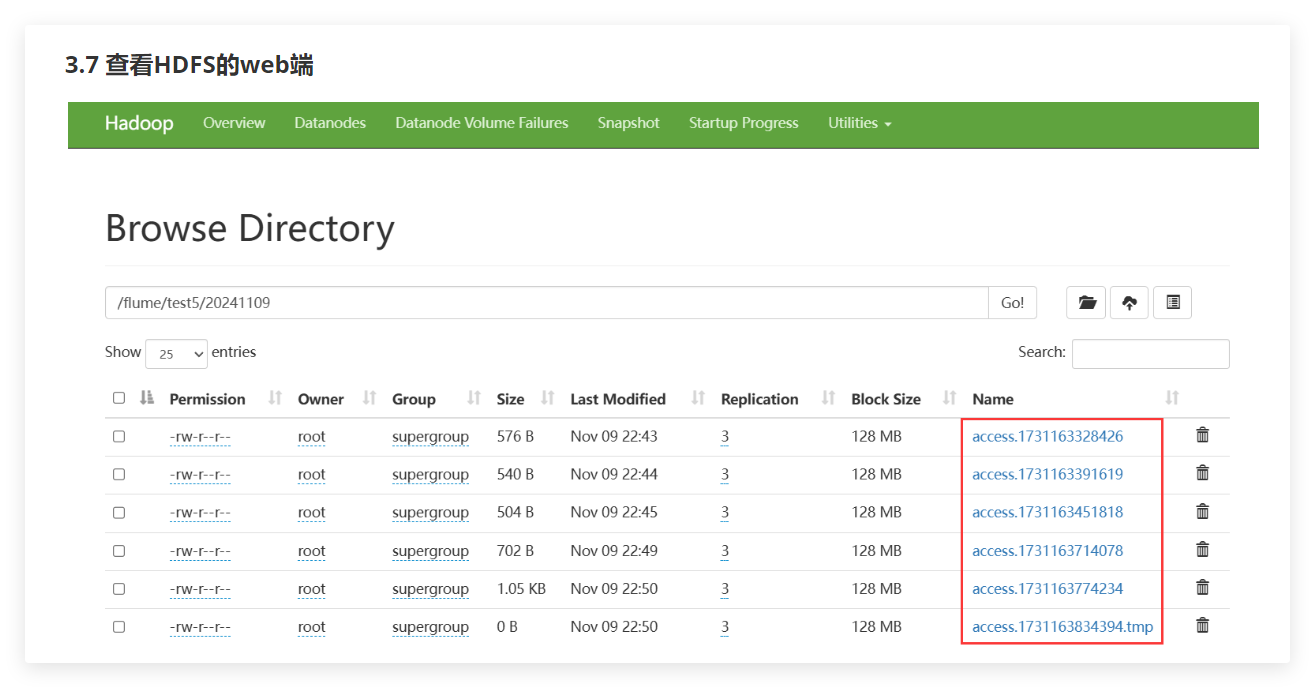
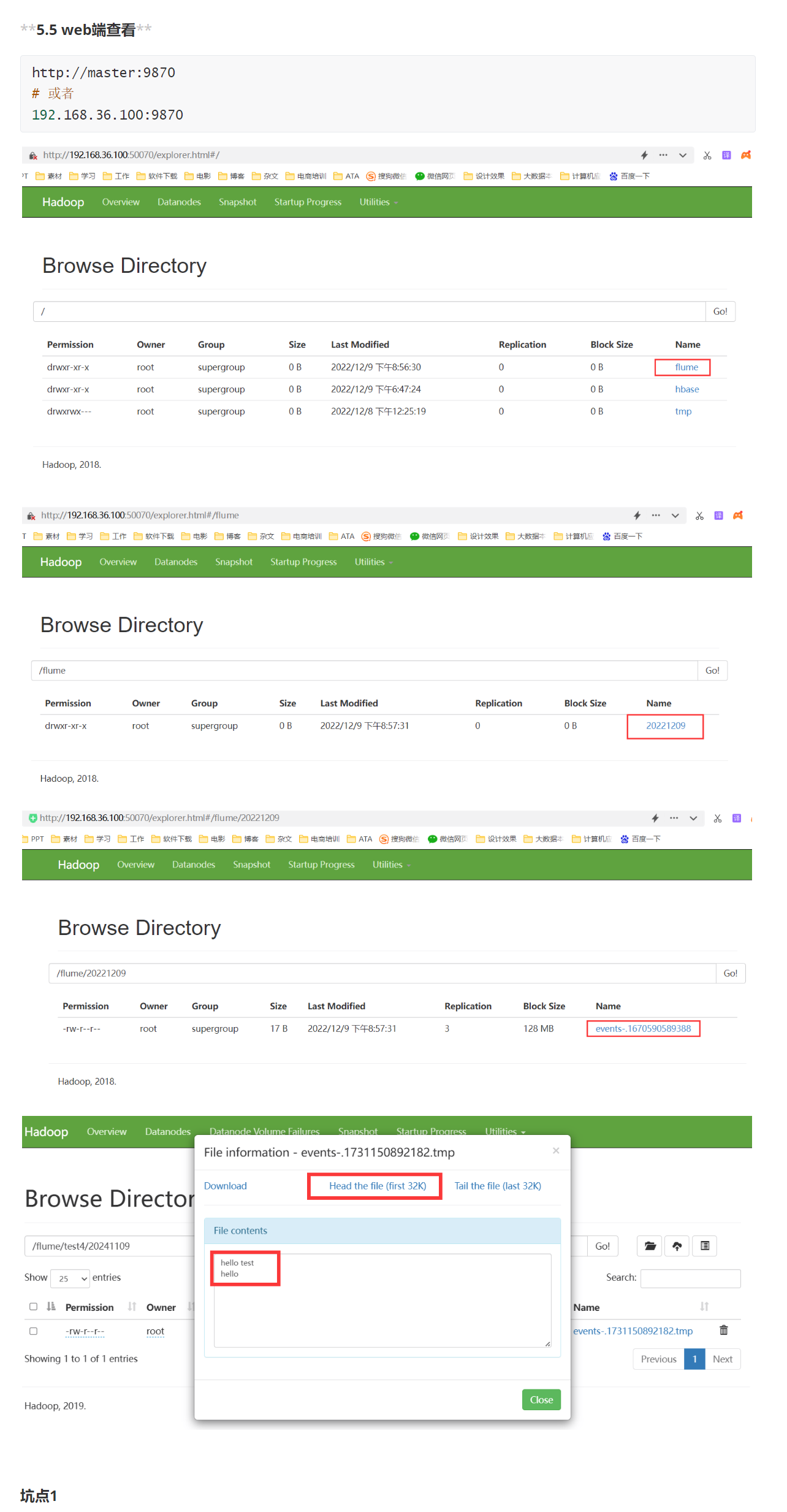
检查 HDFS 的 /flume/test3/当天的日期 目录,确认日志文件是否成功上传。
# 查看方法一:打开浏览器,输入以上网址
http://master:9870
# 或者
http://192.168.36.100:9870
# 查看方法二:命令法
# 在slave2下运行下面的命令,查看hdfs上的文本内容
hdfs dfs -ls -R /
hdfs dfs -cat /flume/test3/当天的日期/*5.实验报告:
编写实验报告,其中包括配置文件的解释、启动过程、遇到的问题及其解决方案,以及成功传输日志到 HDFS 的证据截图。
实验4:flume采集目录中更新的文件到hdfs
【实验任务】
在 slave1 上监控目录,通过 Avro Sink 将数据发送给 master;再由 master 写入 HDFS。
【实验目标】
理解并掌握 Flume 的 Source、Channel、Sink 三大核心组件 的作用与配置方法。
熟练使用 spooldir Source 监控文件目录,并通过 Avro Sink / Avro Source 完成多节点数据传输。
能够将采集到的数据写入 HDFS,并理解 文件滚动规则(按大小、按时间切换文件) 的作用。
通过本实验掌握 Flume 在分布式日志采集中的典型应用场景,为后续 Kafka/Flink 流式处理实验打下基础。
✅ Flume 数据流向图(文件 → spooldir → Avro → Memory → HDFS)
1. 在slave1节点上配置test4_file_avro.conf 文件
# 在slave1节点上操作
cd /opt/apps/flume/conf
# 创建空文件
touch test4_file_avro.conf
# 双击编辑此文件,并添加以下内容配置文件作用:
这个配置文件用于在 slave1 主机 上持续监控某个文件夹,只要有新文件被放入这个目录,Flume 就会自动读取其中的内容,并把这些数据写入 File Channel(磁盘缓存) 进行临时保存。
随后,Flume 会把缓存中的数据通过 Avro 协议(一种高效的大数据传输格式)发送到 master 主机上另一个 Flume Agent 的端口。最终实现: 📌 slave1 → 采集文件内容 📌 File Channel → 缓存保证不丢数据 📌 Avro Sink → 把数据安全传到 master
这样 slave1 的文件数据就能稳定、可靠地传输到 master 上进行后续处理或存储。
配置test4_file_avro.conf 文件内容如下:

2.在slave1 上创建创建配置中指定的目录
# 创建存储 Channel 数据的目录
mkdir -p /opt/apps/flume/data
# 创建存储 Channel 检查点的目录
mkdir -p /opt/apps/flume/data/flume/checkpoint3.创建监听日志文件目录log_data目录(必须为空,否则后面会报错)
# 在slave1上创建
cd /opt/apps/flume
mkdir log_data4. 在master节点上配置test4_avro_hdfs.conf文件
在master节点上面创建test4_avro_hdfs.conf文件,编辑配置
cd /opt/apps/flume/conf
# 创建空文件
touch test4_avro_hdfs.conf
# 双击编辑文件,添加以下内容配置文件作用: 这个配置文件用于在 master 主机 上开启一个 Flume Agent,用来接收从 slave1 发送过来的 Avro 数据。 接收到的事件会先被写入 Memory Channel(内存缓存),再由 HDFS Sink 按日期目录的形式存入 HDFS 中。 同时,HDFS Sink 会根据 文件大小(128MB)或时间间隔(60 秒) 自动切换到新的文件,进行日志分片管理。
简单来说,这份配置实现了:
📌 master 主机:接收 Avro 数据 📌 内存缓存:短期存放数据、再转交 Sink 📌 HDFS 写入:按日期分目录、自动滚动文件
添加以下内容:
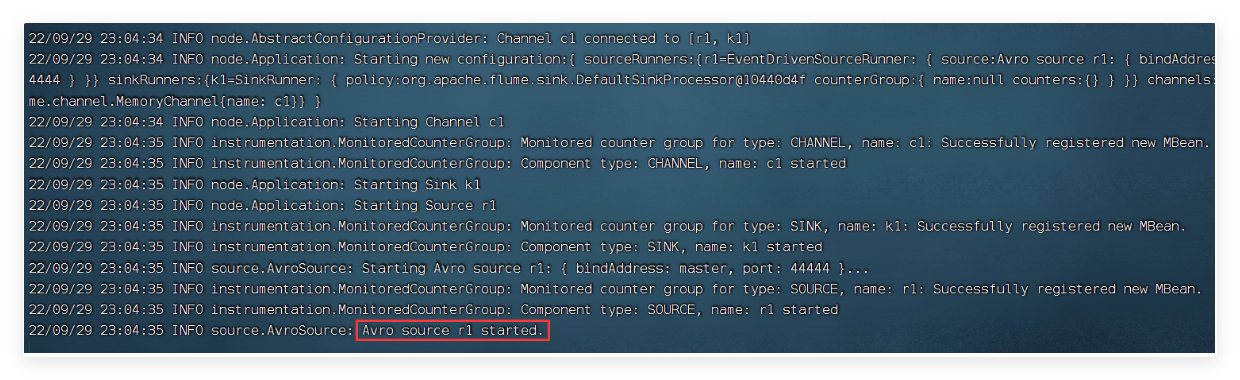
5. 启动flume
5.1 先启动master节点的flume (如果先启动slave上的会导致拒绝连接)
# 在master节点上操作
cd /opt/apps/flume/
# 启动flume
flume-ng agent \
-n a1 \
-c conf \
-f /opt/apps/flume/conf/test4_avro_hdfs.conf \
-Dflume.root.logger=INFO,console
解释:
flume-ng# Flume的启动脚本,启动时需要指定Agent的名字、配置文件的目录和配置文件的名称-n a1# 指定我们这个agent的名字-c conf# 指定flume自身的配置文件所在目录,包含flume-env.sh和log4j的配置文件-f /opt/apps/flume/conf/test4_avro_hdfs.conf# 使用指定的采集方案(配置文件)-Dflume.root.logger=INFO,console# 表示将运行日志输出到控制台
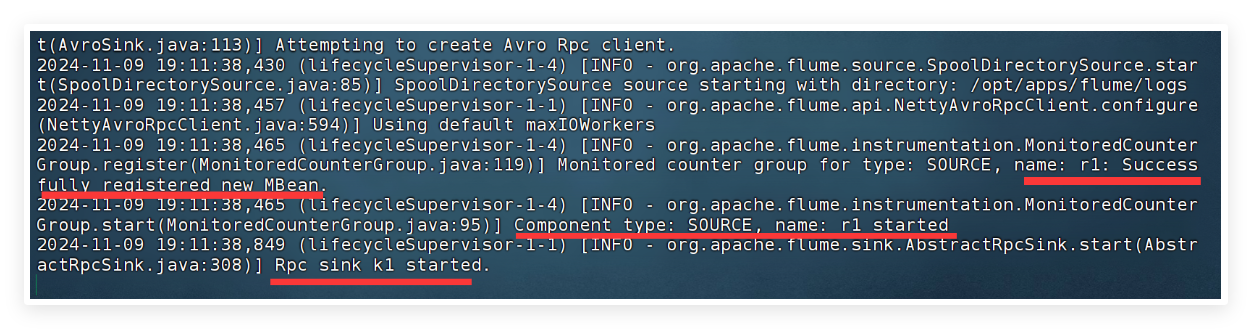
5.2 在slave1节点上启动test4_file_avro.conf
cd /opt/apps/flume
# 运行flume采集和监听日志目录
flume-ng agent \
-n a1 \
-c conf \
-f /opt/apps/flume/conf/test4_file_avro.conf \
-Dflume.root.logger=INFO,console
5.3 启动成功后,在slave2上编辑文件并发送到slave1的监听目录下
# 在slave2下操作
cd ~
touch test
# 双击打开并编辑此文件,添加以下内容
hello test
hello将其复制到slave1监听目录/opt/apps/flume/log_data目录下
scp test slave1:/opt/apps/flume/log_data/
注意:不要将相同文件名的文件复制到监听目录 /opt/apps/flume/log_data,否则会报错:File name has been re-used with different files. Spooling assumptions violated for /opt/apps/flume/logs/test2.COMPLETED.
原因:Flume 的 Spool Directory Source 组件会监视目录中新文件,并在处理完成后将文件标记为已完成(COMPLETED)。如果相同文件名被重复使用,Flume 会认为该文件已处理过,从而导致错误。
解决方法:删除相同名称但内容不同的文件 test 并重新启动 Flume。如果需要重复测试,确保删除 test 文件或使用不同的文件名。

实验5:Flume多节点分布式日志采集与集中存储实验
实验任务: 在 slave1 和 slave2 上使用 Flume 实时采集 access.log 日志内容,通过 Avro Sink → Avro Source 将两台服务器的日志数据汇总到 master 节点,再由 master 将数据写入 HDFS,完成 “多节点采集 → 中央汇总 → HDFS 集中存储” 的完整流程。
【实验目的】
掌握 Flume 的
Exec Source和Avro Sink的配置方法及实际应用,了解其在日志采集与传输中的作用。理解 Flume 跨节点的数据传输架构,熟悉分布式日志数据采集和传输的配置与实现。
实现多节点日志数据的实时采集与汇总,将数据统一上传至 HDFS,并按日期分区存储,以便高效管理和后续分析。
【实验思路】
配置并启动日志采集服务:
在
slave1和slave2上,通过配置test5_file_avro.conf文件,使用Exec Source实时监控access.log文件内容,将新增日志数据作为事件采集到 Flume 中。采集的事件数据使用
File Channel进行缓存,确保数据传输的可靠性。使用
Avro Sink将数据传输至master节点。配置并启动日志汇总服务:
在
master节点配置test5_file_hdfs.conf,使用Avro Source接收slave1和slave2传输的数据。使用
HDFS Sink将接收到的数据存储到 HDFS 中的指定目录,并按日期分区,以便管理日志。设置文件滚动策略,确保数据文件按时间间隔或大小进行滚动存储,避免单个文件过大。
生成并传输测试数据:
在
slave1和slave2上创建日志生成脚本generate_log.sh,以模拟日志写入的实时性和连续性。运行脚本,持续向
access.log中写入日志数据,通过 Flume 自动传输到master,并最终存储在 HDFS 中。验证实验结果:
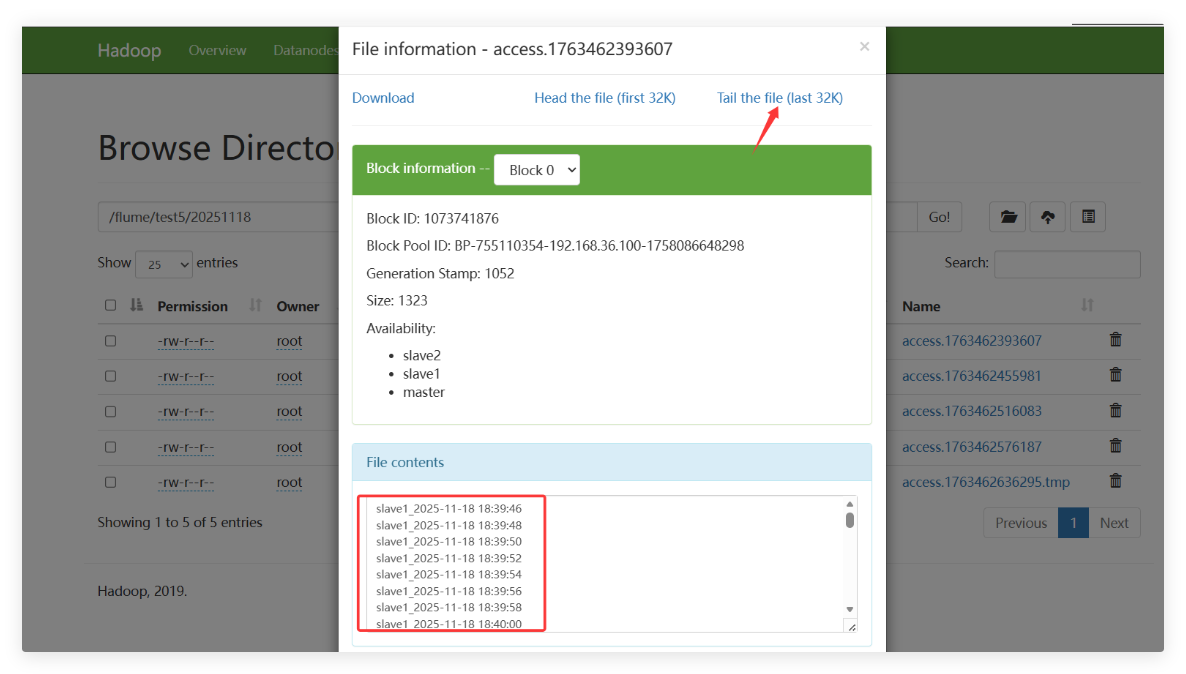
检查 HDFS 文件系统,确认数据是否按日期分区成功存储。
查看日志文件内容,验证
slave1和slave2的日志数据是否正确汇总到 HDFS,确保整个数据采集、传输和存储流程的有效性。
【实验步骤】
1. 日志收集服务配置
在master节点编辑slave1和slave2共用的上传日志的配置test5_file_avro.conf
1.1 编写test5_file_avro.conf文件
cd /opt/apps/flume/conf
# 创建空文件
touch test5_file_avro.conf
# 双击打开编辑此文件
配置内容作用:在 slave1 或 slave2 上实时采集日志文件 access.log 中的新增内容,并通过 File Channel 缓存数据以确保可靠性,采集的数据将通过 Avro Sink 传输至 master 服务器,以便集中化存储和管理。
配置内容如下:
# 配置test5_file_avro.conf
## 定义 Agent 名称
# 为 Flume 配置的 Agent 定义各组件的名称
a1.sources = r1
a1.channels = c1
a1.sinks = k1
## 配置Souce组件
# 配置 source 类型为 exec,从外部命令或脚本中读取数据
a1.sources.r1.type = exec
# 指定了 Flume source 的数据读取命令,配置执行命令为 tail -F,实时跟踪 access.log 文件中的新增内容
a1.sources.r1.command = tail -F /opt/apps/flume/logs/access.log
## 配置Channel组件
# 使用 File Channel,把数据先临时存到磁盘文件中
a1.channels.c1.type = file
# 数据文件保存的位置(Channel 缓存的数据都放在这个目录里)
a1.channels.c1.dataDirs = /opt/apps/flume/data
# 创建检查点目录,用于存储Channel的状态和偏移信息【读取位置】,如果Flume意外关闭,用来断点恢复
a1.channels.c1.checkpointDir = /opt/apps/flume/data/flume/checkpoint
# Channel 最大能存 1000 条数据(满了就暂停接收,等 Sink 消费掉再继续)
a1.channels.c1.capacity = 1000
# 每次 Source/Sink 读写数据的最大数量(每次处理 100 条)
a1.channels.c1.transactionCapacity = 100
# 配置Sink组件
# 配置 sink 类型为 avro,"k1" 会将数据以 Avro 格式传输到指定的目标
a1.sinks.k1.type = avro
# hostname 指定数据发送的目标主机名称或 IP 地址
a1.sinks.k1.hostname = master
# port 指定发送数据的目标 RPC 端口号
a1.sinks.k1.port = 44444
## 将 Source 与 Sink 和 Channel 连接起来
# 将 source r1 绑定到 channel c1,使数据从 source r1 发送到 channel c1
a1.sources.r1.channels = c1
# 将 sink k1 绑定到 channel c1,使 sink k1 从 channel c1 接收数据
a1.sinks.k1.channel = c11.2 创建配置中指定的目录
# 创建存储 Channel 数据的目录
mkdir -p /opt/apps/flume/data
# 创建存储 Channel 检查点的目录
mkdir -p /opt/apps/flume/data/flume/checkpoint1.3 生成测试数据的脚本
脚本作用:这个脚本每 2 秒生成一条“日志数据”,内容包含当前主机名 + 当前时间,一边显示在终端,一边追加写入到
access.log中,用来模拟实时不断产生的日志。数据格式如:
master_1697456220
# 在master下创建“生成测试数据”的脚本
cd /opt/apps/flume/logs
# 创建空文件
touch generate_log.sh脚本内容如下:
#!/bin/bash
# 无限循环,持续生成日志数据
while true
do
# 获取当前日期时间(精确到秒)
curr_time=`date +"%Y-%m-%d %H:%M:%S"`
# 获取当前主机名
name=`hostname`
# 输出到终端,并追加写入 access.log
echo "${name}_${curr_time}" | tee -a /opt/apps/flume/logs/access.log
# 每 2 秒生成一条日志
sleep 2
done保存退出后执行
# 进入目录
cd /opt/apps/flume/logs
# 更改文件的权限
chmod 777 generate_log.sh
# 运行脚本,结束可以按Ctrl+C
./generate_log.sh作用:该脚本通过无限循环生成包含主机名和时间戳的日志数据,并将其同时输出到终端和指定的日志文件 access.log 中,用于模拟日志生成。数据格式如:master_1697456220
2. 日志汇总服务配置
在master上编写test5_avro_hdfs.conf
cd /opt/apps/flume/conf
# 创建空文件
touch test5_avro_hdfs.conf
# 双击打开编辑此文件配置内容作用:在 master 上通过 Avro Source 接收来自 slave1 或 slave2 的日志数据,该数据由 access.log 文件中实时新增的内容生成。采集的数据通过 Memory Channel 暂存,以确保传输过程的高效和可靠性。最终,数据通过 HDFS Sink 存储到 HDFS 中,按日期分区管理,以便集中化存储和后续分析。
配置文件如下:
# 配置test5_avro_hdfs.conf
## 定义 Agent 名称
# 为 Flume 配置的 Agent 定义各组件的名称
a1.sources=r1
a1.channels=c1
a1.sinks=k1
# 配置 Source 组件 r1
# Source 是数据的输入端,负责从监听 Avro 客户端并接收数据
a1.sources.r1.type = avro
# 绑定 IP 地址为 0.0.0.0,表示源(source)将监听并接受来自所有网络接口的连接。
a1.sources.r1.bind = 0.0.0.0
# 监听的端口号为 44444,Avro 客户端将通过该端口发送数据
a1.sources.r1.port = 44444
# 为 source 配置一个拦截器i1,用于添加时间戳。interceptor[ˌɪntəˈseptəz] 拦截
a1.sources.r1.interceptors = i1
# 配置拦截器 i1 的类型为 timestamp,作用是自动在每个事件中添加时间戳
a1.sources.r1.interceptors.i1.type = timestamp
# 配置 Channel 组件 c1
# Channel 是 Flume 中用于连接 Source 和 Sink 的通道,存储传输过程中的数据
# # 配置Channel通道类型为 memory,用于在内存中缓存数据
a1.channels.c1.type = memory
# Channel通道最多存 1000 条事件,满了就暂停接收,等消费后再继续
a1.channels.c1.capacity = 1000
# source 和 sink 从内存 channel 每次事务传输的最大事件数量为100
a1.channels.c1.transactionCapacity = 100
# 配置Sink组件
# Sink 是数据的输出端,用于将数据写入 HDFS
a1.sinks.k1.type=hdfs
# 设置 HDFS 路径,将数据按日期存储在 /flume/test5/ 目录下
a1.sinks.k1.hdfs.path = hdfs://master:9000/flume/test5/%Y%m%d
# 指定在hdfs上生成的文件名前缀
a1.sinks.k1.hdfs.filePrefix = access
# 设置 HDFS 文件类型为 DataStream,以流式方式写入数据
a1.sinks.k1.hdfs.fileType = DataStream
# 设置数据写入 HDFS 的格式为文本(Text),每条事件数据以纯文本格式存储
a1.sinks.k1.hdfs.writeFormat=Text
# 设置文件滚动时间间隔为 60 秒,每 60 秒生成一个新文件,以控制文件大小和频率;
a1.sinks.k1.hdfs.rollInterval = 60
# 不按文件大小滚动(0 表示关闭),配合 rollInterval 只按时间滚动
a1.sinks.k1.hdfs.rollSize = 0
# 不按事件条数滚动(0 表示关闭),所有事件都写入当前文件,直到时间到达 rollInterval
a1.sinks.k1.hdfs.rollCount = 0
## 将 Source 与 Sink 和 Channel 连接起来
# 将 source r1 绑定到 channel c1,使数据从 source r1 发送到 channel c1
a1.sources.r1.channels = c1
# 将 sink k1 绑定到 channel c1,使 sink k1 从 channel c1 接收数据
a1.sinks.k1.channel = c1 3. 运行服务测试
3.1 在master节点分发slave.conf到slave节点
# 配置好的`test5_file_avro.conf`分发到`slave1/slave2`节点上
scp /opt/apps/flume/conf/test5_file_avro.conf slave1:/opt/apps/flume/conf/
scp /opt/apps/flume/conf/test5_file_avro.conf slave2:/opt/apps/flume/conf/
# 把生成日志的脚本`generate_log.sh`分发到`slave1/slave2`节点上
scp /opt/apps/flume/logs/generate_log.sh slave1:/opt/apps/flume/logs
scp /opt/apps/flume/logs/generate_log.sh slave2:/opt/apps/flume/logs3.2 在master节点运行flume服务
注意:必须先启动master节点的flume【如果先启动slave上的会导致拒绝连接】
# 在Master节点操作
cd /opt/apps/flume
# 运行flume
flume-ng agent \
-n a1 \
-c conf \
-f conf/test5_avro_hdfs.conf \
-Dflume.root.logger=INFO,console3.3 在slave1上面运行flume服务
# 在slave1上操作
cd /opt/apps/flume
# 运行flume
flume-ng agent \
-n a1 \
-c conf \
-f conf/test5_file_avro.conf \
-Dflume.root.logger=INFO,console3.4 复制slave1第二个终端窗口执行生产测试数据的日志的脚本
# 在slave1第二个终端窗口上操作
cd /opt/apps/flume/logs
# 运行脚本
./generate_log.sh
# 如需要结束运行按ctrl+C强制退出3.5 在slave2上面运行flume服务
# 在slave2上操作
cd /opt/apps/flume
# 运行flume
flume-ng agent \
-n a1 \
-c conf \
-f conf/test5_file_avro.conf \
-Dflume.root.logger=INFO,console3.6 复制slave2第二个终端窗口执行生产测试数据的日志的脚本
# 在slave2第二个终端窗口上操作
cd /opt/apps/flume/logs
# 运行脚本
./generate_log.sh
# 如需要结束运行按ctrl+C强制退出