一、Hive 基础概念与执行原理
1.1 什么是 Hive?
Hive 是一个 运行在 Hadoop 上的大数据分析工具,它不是数据库,而是一个类似 SQL 的工具,方便我们在 Hadoop 上分析数据。
它把存储在 HDFS(分布式文件系统)中的数据,看成一张张表,使用 HQL(Hive SQL)来查询数据。
💡 就像我们用 Excel 管理表格,Hive 就是帮我们“在 Hadoop 上查表格”的工具。
1.2 Hive 的特点
| 特点 | 说明 |
|---|---|
| 不存数据 | 数据都存储在 HDFS 中 |
| 不算数据 | 数据处理靠 MapReduce 或 Spark |
| 会“翻译” | 把 HQL 翻译成 MapReduce 作业去运行 |
1.3 Hive 怎么存数据?
Hive 不是数据库,不改变数据内容,只是“指向”了数据位置。
数据通常以 文本文件(如 CSV、TXT、ORC、Parquet)的方式存在。
加载数据时,Hive 会把文件放到 HDFS 的某个目录下。
Hive 表本质是 HDFS 上的目录 + 元数据(表结构)。
1.4 Hive 适合用在哪些场景?
Hive 非常适合做:
大批量数据分析(离线分析)
数据仓库建模
数据预处理(ETL)
不适合做:
实时查询或秒级响应
高频数据插入/修改
1.5 Hive 的架构原理
Hive 是怎么工作的?
Hive 不是数据库,它是一个“翻译官”,把我们写的 HQL(Hive SQL)翻译成 Hadoop 或 Spark 能执行的程序,然后在集群中处理数据,最后把结果返回。

hive的架构图1:

步骤说明(图中1~6步骤)
| 步骤 | 流程说明(结合图示) | 教学讲解要点(通俗化) |
|---|---|---|
| ① 用户提交 HQL 查询 | 用户通过命令行、网页或 JDBC 提交 SQL(HQL) | 比如:SELECT * FROM users |
| ② SQL 语法解析与编译 | Hive Driver 内部依次完成: • 解析器(Interpreter):检查语法是否正确 • 编译器(Compiler):把语句翻译成逻辑执行计划 • 优化器(Optimizer):优化执行逻辑,提高效率 • 执行器(Executor):准备将任务提交给 Hadoop 引擎执行 | Driver 内完成:解析器 → 编译器 → 优化器→ 执行器 |
| ③ 查询元数据 | Hive 向 Metastore 查表结构(字段名、分区、数据路径等) | 类似查字典或地图,确认数据在哪、怎么处理 |
| ④ 生成任务并提交执行 | 执行计划被翻译成 MapReduce 程序,交给 YARN 调度执行 | Hive 自己不干活,只负责“交办任务” |
| ⑤ Hadoop 集群执行 | MapReduce 程序从 HDFS 中读取文件(如 china_user.txt),并开始处理 | 真正的数据处理在这一步完成 |
| ⑥ 返回结果展示 | 任务执行完后,结果返回给用户(终端或界面上显示) | 最后看到查询结果 |
Hive 架构图2:

Hive 查询五步法
| 步骤 | 内容说明 | 通俗理解 |
|---|---|---|
| ① | 提交查询 | 用户写一条 HQL 查询 |
| ② | 查表结构 | 去 MetaStore 查表字段、路径 |
| ③ | 编译并优化执行计划 | Driver 编译器和优化器 |
| ④ | 提交执行任务 | 提交给 MapReduce 或 Spark |
| ⑤ | 返回查询结果 | 执行完把结果返回用户 |
1.6 Hive 与 RDBMS 的比较
| 比较维度 | Hive(数据仓库) | RDBMS(关系型数据库) |
|---|---|---|
| 查询语言 | HQL(类 SQL) | 标准 SQL |
| 存储位置 | HDFS(分布式文件系统) | 本地文件系统 |
| 数据操作 | 读多写少,不建议频繁更新 | 支持增删改查(实时操作) |
| 修改方式 | 通常是覆盖或追加整批数据 | 支持行级更新或删除 |
| 索引支持 | 简单索引(如 Bitmap) | 支持多种索引(B+树、哈希等) |
| 执行方式 | MapReduce 或 Spark 分布式执行 | 本地执行器单机运行 |
| 执行速度 | 延迟较高(几秒到几分钟) | 延迟低(毫秒级) |
| 可扩展性 | 高,可水平扩展(增加节点) | 扩展性有限 |
| 数据规模 | 支持海量(TB/PB 级) | 适合中小型数据(GB 级以内) |
| 分区功能 | 支持分区表,提高查询效率 | 支持分区,但常用于垂直/水平切分 |
总结:
Hive 更像是一个“大数据批量分析平台”,不是数据库;
Hive 不适合用来做“实时增删改查”,而是“批量读+分析”;
Hive 的优势在于“能处理非常大、非常慢的数据”,比如一天跑一次全表分析;
RDBMS 适合“实时响应型业务系统”,比如网页登录、下订单等。
二、Hive 元数据与服务机制
2.1 Hive 元数据与 Metastore 是什么?
一、什么是元数据?
元数据是 Hive 中关于数据库、表名、字段、分区、数据位置等的“描述信息”;
举例:
users表有哪些字段、存在哪、是否有分区等。
Hive 自身不保存数据内容,但必须知道数据结构和存储位置,这些就由元数据来记录。
二、元数据存在哪?
默认使用内嵌数据库(如 Derby);
生产环境通常使用外部数据库(如
MySQL);所有元数据集中管理,便于多客户端共享。
三、什么是 Metastore?
Metastore 是 Hive 的元数据访问服务中心,本身不保存数据,而是将元数据统一托管在关系型数据库中,并提供统一接口供 Hive 客户端(如 CLI、HiveServer2、Beeline 等)访问。
Metastore 服务的优势在于:
集中管理:多个客户端(如 Hive CLI、HiveServer2、Beeline 等)可以同时连接 Metastore 服务,统一访问元数据信息,而无需各自直接连接底层的 MySQL 数据库。
安全性高:客户端只与 Metastore 通信,不需要接触 MySQL 的账号密码,从而提升了元数据的安全隔离性和系统整体安全性。
通过 Metastore 服务,Hive 的元数据可以被多个客户端方便、安全地访问和管理。

2.2 Hive 的运行模式与部署建议
| 模式 | 特点 | 适用场景 |
|---|---|---|
| 伪分布式模式 | Hive、Hadoop 运行在单机上 | 开发/学习 |
| 完全分布式模式 | 多节点 Hadoop + Hive + MySQL 协作运行 | 正式生产环境 |
📌 Hive 只需安装在主节点或任意一个管理节点上,因计算任务最终交由 Hadoop 集群执行。
2.3 Metastore 三种部署方式(重点内容)
在 Hive 中,元数据存储(Metastore)服务可以通过三种模式进行配置:内嵌模式、本地模式和远程模式。
① 内嵌模式(Embedded)
| 项目 | 描述 |
|---|---|
| 运行方式 | Hive 与 Metastore 同进程运行 |
| 使用数据库 | Derby(单用户、内嵌式) |
| 是否支持并发 | ❌ 不支持多客户端连接 |
| 适用场景 | 学习、单用户测试 |
📌 特点:简单、默认,但只能一个客户端用。

图示说明:
Hive Driver:负责发起并解析用户的 SQL 查询;
Metastore:管理和提供元数据服务;
Derby:作为内嵌数据库,保存所有的 Hive 元数据信息。
模式特点:
Hive、Metastore 和 Derby 运行在同一个 JVM 进程中;
Derby 是单用户数据库,只能在同一时刻接受一个客户端连接;
适合用于 开发测试环境,不推荐在生产环境使用。
② 本地模式(Local)
| 项目 | 描述 |
|---|---|
| 运行方式 | Hive 与 Metastore 分进程,部署在同一台机器 |
| 使用数据库 | 外部数据库(如 MySQL) |
| 是否支持并发 | 支持多个 Hive 进程共享元数据 |
| 适用场景 | 小型集群、教学实训 |
📌 特点:支持多客户端访问,但仍部署在同一台机器上。

图示说明:
Hive Driver:负责发起 SQL 查询,并与 Metastore 服务进行交互;
Metastore:作为一个独立的服务进程运行,集中对外提供元数据服务;
MySQL:作为外部数据库,存储所有 Hive 的元数据信息,支持多用户同时访问。
模式特点:
Hive Driver 与 Metastore 分开部署,通过 Thrift 协议进行远程通信;
Metastore 服务可供 多个 Hive 客户端或服务实例同时访问;
MySQL 提供高并发能力,支持生产环境下多用户的元数据访问需求;
推荐用于 企业级部署与生产环境,具备更强的可扩展性和稳定性。
③ 远程模式(Remote)[ 推荐部署方式]
| 项目 | 描述 |
|---|---|
| 运行方式 | Metastore 单独运行在一台服务器上 |
| 使用数据库 | 外部数据库(MySQL) |
| 是否支持并发 | 支持多个 HiveServer2、工具共享 |
| 适用场景 | 企业生产环境、高可用大数据平台 |
📌 优势:
独立服务,便于扩展;
多个工具(如 Hive CLI、Beeline、Hue、Impala 等)可共用;
与企业部署一致。

图示说明:
Beeline CLI(Hive 新客户端):通过 HiveServer2 发起 SQL 请求;
Hive CLI(Hive 旧客户端):早期使用方式,现已逐步被淘汰;
HiveServer2:提供统一的远程服务入口,支持多客户端访问;
Metastore:作为一个独立进程运行,负责提供元数据管理服务;
MySQL:作为外部数据库,持久化存储 Hive 的所有元数据信息;
Hue:基于 Web 的图形界面工具,提供可视化查询与交互;
Apache Impala:分布式 SQL 查询引擎,可共享 Hive 元数据;
Apache Pig:用于大规模数据处理的脚本语言平台;
HCatalog:提供统一的元数据访问服务,支持 Hadoop 系统中多种工具共享 Hive 元数据。
模式特点:
Metastore 以 远程服务方式运行,所有组件通过网络调用元数据;
支持 Beeline、Hue、Pig、Impala 等工具共享 Hive 元数据;
提供更强的 系统扩展性与组件兼容性,适合企业级平台部署;
推荐用于生产环境,满足多用户并发访问与元数据集中管理的需求。
本系列课程中使用企业推荐模式--远程模式部署。
三、Hive的安装部署
1、前期准备
在开始安装和配置 Hive 之前,请确保以下组件已正确安装和配置:
JDK 1.8
Hadoop 3.1.3 集群
MySQL 5.7.27
2、安装并配置
2.1 下载hive
首先需要下载Hive安装包文件apache-hive-3.1.2-bin.tar.gz
[Hive官网下载地址]http://archive.apache.org/dist/hive/
2.2 解压并改名
将下载的 apache-hive-3.1.2-bin.tar.gz 文件上传到master节点的 /opt/software 目录下,并解压到 /opt/apps 目录中,然后将文件夹重命名为 hive。
cd /opt/software
tar -zxvf apache-hive-3.1.2-bin.tar.gz -C /opt/apps # 解压到/opt/apps中
cd /opt/apps/
mv apache-hive-3.1.2-bin hive # 将文件夹名改为hive 2.3 配置环境变量
编辑文件: /etc/profile
# 添加以下信息
# Hive 安装路径
export HIVE_HOME=/opt/apps/hive
export PATH=$PATH:$HIVE_HOME/bin使环境变量配置生效
source /etc/profile
2.4 安装mysql环境
前期已经配置完成!
2.5 配置 Hive 接入 MySQL 元数据库
为实现 Hive 在生产环境中高效稳定运行,我们选择使用 MySQL 数据库 来存储 Hive 的元数据信息(如表结构、分区信息等),而不使用默认的 嵌入式 Derby 数据库。
第一步:下载 MySQL JDBC 驱动
前往官方网站下载 JDBC 驱动:
推荐版本:mysql-connector-java-5.1.40.tar.gz
该驱动包可用于 Java 应用程序(包括 Hive)连接 MySQL 数据库。
第二步:上传并解压驱动文件
将 mysql-connector-java-5.1.40.tar.gz 上传到 master 节点的 /opt/software 目录中,然后执行以下命令:
cd /opt/software
tar -zxvf mysql-connector-java-5.1.40.tar.gz # 解压第三步:拷贝驱动到 Hive 安装目录
将解压后的 .jar 驱动文件复制到 Hive 的 lib 目录下:
cp mysql-connector-java-5.1.40/mysql-connector-java-5.1.40-bin.jar /opt/apps/hive/lib
✅ 说明:Hive 在启动时会从其 lib 目录中加载 JDBC 驱动,确保该
.jar文件存在于 Hive 安装路径下。
2.6 配置 Hive 环境变量文件 hive-env.sh
配置目的:
为确保 Hive 能正常调用 Java、Hadoop 以及其自身的相关功能,我们需要配置环境变量文件
hive-env.sh。
第一步:复制模板文件
进入 Hive 的配置文件目录,并复制默认模板为正式配置文件:
cd /opt/apps/hive/conf
cp hive-env.sh.template hive-env.sh第二步:编辑 hive-env.sh
使用编辑器打开并修改以下内容:
编辑文件: hive-env.sh
填写如下配置:
# ========== Java 环境 ==========
export JAVA_HOME=/opt/apps/jdk
# ========== Hadoop 依赖 ==========
export HADOOP_HOME=/opt/apps/hadoop
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HADOOP_MAPRED_HOME=$HADOOP_HOME
# 设置 Hadoop 的 Classpath,解决 Hive 执行 MapReduce 时找不到类的问题
export HADOOP_CLASSPATH=$($HADOOP_HOME/bin/hadoop classpath)
# ========== Hive 本身 ==========
export HIVE_HOME=/opt/apps/hive
export HIVE_CONF_DIR=/opt/apps/hive/conf
# 指定 Hive 的辅助 JAR 文件路径(用于加载 Hive 扩展或自定义 UDF 函数等)
export HIVE_AUX_JARS_PATH=/opt/apps/hive✅ 说明:
JAVA_HOME、HADOOP_HOME是 Hive 运行所依赖的基础环境;HADOOP_CLASSPATH用于动态获取 Hadoop 依赖路径,防止任务运行时报错;HIVE_AUX_JARS_PATH可扩展 Hive 功能,例如自定义函数(UDF)或额外连接驱动。
2.7 配置hive-site.xml
配置目的:
hive-site.xml是 Hive 的核心配置文件,用于定义 Hive 的元数据存储方式、仓库路径、服务端口等信息。
第一步:进入配置目录并创建配置文件
cd /opt/apps/hive/conf
# 第二种方法:使用touch创建空文件
touch hive-site.xml第二步:填写配置内容【以下是典型的 Hive 远程 Metastore 模式配置】
<configuration>
<!-- 设置连接到用于存储 Hive 元数据的 MySQL 数据库的 JDBC URL -->
<!-- 如果指定的数据库 'hive' 不存在,将在首次连接时自动创建(前提是有建库权限) -->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://master:3306/hive?createDatabaseIfNotExist=true&useSSL=false</value>
</property>
<!-- 配置 Hive 使用的 MySQL JDBC 驱动类 -->
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<!-- 配置连接 MySQL 所需的用户名 -->
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<!-- 配置连接 MySQL 所需的密码 -->
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>
<!-- 关闭元数据存储版本的验证 -->
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
<!-- 关闭元数据存储授权 -->
<property>
<name>hive.metastore.event.db.notification.api.auth</name>
<value>false</value>
</property>
<!-- 设置Hive在HDFS上的默认仓库目录-->
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
<!-- 配置 Hive 客户端(如 Beeline、Spark)通过 Thrift 连接 Metastore 服务的地址 -->
<property>
<name>hive.metastore.uris</name>
<value>thrift://master:9083</value>
</property>
<!-- 设置 HiveServer2 监听的端口号 -->
<!-- 允许客户端使用各种支持JDBC工具和编程语言如SQL来执行查询和管理 Hive -->
<property>
<name>hive.server2.thrift.port</name>
<value>10000</value>
</property>
<!-- 设置 HiveServer2 绑定的主机名【可以跳过此步骤】-->
<property>
<name>hive.server2.thrift.bind.host</name>
<value>master</value>
</property>
<!-- 配置 CLI 输出表头【可以跳过此步骤】-->
<property>
<name>hive.cli.print.header</name>
<value>true</value>
</property>
<!-- 配置 CLI 显示当前数据库【可以跳过此步骤】-->
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
</property>
</configuration>2.8 初始化 Hive 元数据库(使用 MySQL)
配置目的:在 Hive 安装完成后,需初始化元数据库(Metastore)结构,用于存储 Hive 的数据库、表、字段、分区等元数据信息。
操作目标:将 Hive 的元数据结构写入 MySQL,为后续建库建表做好准备。
✅ 解决依赖冲突
查看 Hadoop 中的 Guava 版本
cd /opt/apps/hadoop/share/hadoop/common/lib
ls | grep guava
# 例如:guava-27.0-jre.jar
查看 Hive 中的 Guava 版本
cd /opt/apps/hive/lib
ls | grep guava
# 例如:guava-19.0.jar
替换 Hive 中的 Guava 库
Hive 使用的是 guava-19.0,而 Hadoop 是 guava-27.0,因此需要统一成高版本。
cd /opt/apps/hive/lib
rm -f guava-19.0.jar # 删除旧版本
cp /opt/apps/hadoop/share/hadoop/common/lib/guava-27.0-jre.jar . # 复制新版本
初始化 Hive 元数据库:
schematool -initSchema -dbType mysql -verbose
-initSchema:表示初始化 Hive 的元数据表结构。
-dbType mysql:指定使用 MySQL 作为 Hive 的元数据库。
-verbose:启用详细模式,输出更多的操作细节,方便调试和确认操作过程。
✅ 初始化成功时的提示
在终端中滚动显示日志后,若出现以下内容说明初始化完成:
Initialization script completed → # 初始化脚本执行完毕;
schemaTool completed → # schematool 工具完成整个初始化流程2.9 Hive 3.1.2 版本命令行日志过多问题的解决方案
问题描述:在使用 Hive 3.1.2 的过程中,进入 hive Shell 后执行任意操作时,命令行窗口会持续输出大量日志信息(如 INFO、DEBUG 级别日志),严重影响查询结果的阅读和调试体验。
解决方法:
通过手动创建并配置 Log4j,控制日志级别。
操作路径
# 进入 Hive 安装目录的配置目录:
cd /opt/apps/hive/conf新建或编辑日志配置文件:
创建一个文件 log4j.properties(如果已有同名文件,请确认不覆盖其他设置):
touch log4j.properties
添加以下内容:
log4j.rootLogger=ERROR
补充说明:日志级别调整为
ERROR,屏蔽 INFO 和 DEBUG 、WARN日志输出。
3、启动hive
3.1 Hive 客户端类型简介
Hive 提供两种主要客户端工具用于执行 SQL 查询:
1. Hive CLI(命令行客户端)
Hive CLI 是本地执行 Hive SQL 的传统方式,用户可直接通过命令行与 Hive 交互。
执行流程:Hive CLI 本地编译 SQL → 查询 Metastore → 构建 MapReduce 作业 → 提交给 Hadoop 执行。
启动 Hive CLI 时,内部会启动一个
RunJar进程,并默认集成 Metastore 服务。✅ 使用 Hive CLI 时,仅需启动 Metastore 服务。
2. Beeline + HiveServer2(推荐)
Beeline 是 Hive 新推荐的轻量级
JDBC客户端,配合服务端HiveServer2使用。查询流程:Beeline 提交 SQL → HiveServer2 解析执行 → 调用 Metastore 和 Hadoop 执行作业。
支持多用户并发访问,更适合生产环境与权限控制。
✅ 使用 Beeline 时,需启动 Metastore 和 HiveServer2 两个服务。
3.2 启动 Hive 前的准备工作
在运行 Hive 前,请确保以下服务已成功启动:
start-dfs.sh #在master上启动HDFS
start-yarn.sh #在slave1上启动Yarn3.3 交互方式一:Hive CLI 模式
步骤一:启动 Metastore 服务
Metastore 是 Hive 的元数据服务,负责管理数据库、表、字段、位置等信息。
可以通过以下任一方式启动 Metastore:
| 启动方式 | 命令及说明 |
|---|---|
| 前台启动 | hive --service metastore 窗口将被独占 |
后台启动【推荐方式】 | hive --service metastore & 仍输出日志到当前窗口 |
| 完全后台 + 输出重定向 | nohup hive --service metastore > log.txt 2>&1 & |
| 简化后台启动 | nohup hive --service metastore & 日志默认写入 nohup.out |
步骤二:启动 Hive 命令行客户端
hive
进入 Hive CLI 后,可执行 HiveQL 命令:
# 例如:查看数据库
show databases;默认会显示系统数据库
default。
步骤三:退出 Hive
quit;
关键概念说明
| 概念 | 说明 |
|---|---|
| default 数据库 | Hive 安装时自动创建的默认数据库,未指定数据库时所有表默认建在此处。 |
| 表的存储位置 | 默认存放于 HDFS 路径 /user/hive/warehouse/ 下。 |
| 元数据管理 | 使用 MySQL 存储库记录数据库/表的逻辑名称与 HDFS 实际路径之间的映射关系。 |
3.2 交互方式二:Beeline + HiveServer2(官方推荐)
官方推荐使用 Beeline 客户端连接 HiveServer2 服务端的方式进行操作。该模式支持远程访问、多用户并发、安全控制等企业级功能。
3.2.1 修改 Hive 配置(仅首次配置时需操作)
在 Hive 配置文件 /opt/apps/hive/conf/hive-site.xml 中添加以下配置项:
<!-- 禁用 HiveServer2 的用户模拟功能, Hive查询和操作都将以 HiveServer2 进程的所有者身份运行 -->
<!-- 解决了 `User: root is not allowed to impersonate root` 的错误。 -->
<property>
<name>hive.server2.enable.doAs</name>
<value>false</value>
</property>
<!-- 启用 Hive Server2 的主备模式(高可用性功能),解决启动卡顿和类加载错误 -->
<!-- 解决TezConfiguration和NoClassDefFoundError错误 -->
<property>
<name>hive.server2.active.passive.ha.enable</name>
<value>true</value>
</property>💡 如果之前已配置过可跳过此步骤。配置修改后,建议重启 Hive 服务生效。
3.2.2 启动服务端组件服务
此方式需启动 两个服务端组件:
Metastore 元数据管理服务
HiveServer2 查询与远程访问服务
启动方式:后台运行(推荐方法):
hive --service metastore &hive --service hiveserver2 &特点:此启动方式下服务在后台运行,仍会在终端中打印日志,适合调试。
使用上述之一的方法启动服务后,可使用 jps -m 命令检查已启动的进程
如查看到启动两个RunJar,说明两个服务已在后台启动

3.2.3 启动 Beeline 客户端连接 Hive
beeline -u jdbc:hive2://master:10000 -n root
命令说明:
| 参数 | 说明 |
|---|---|
beeline | 启动 Beeline 客户端 |
-u jdbc:hive2://... | 指定连接的 HiveServer2 地址(默认端口为 10000) |
-n root | 指定登录 HiveServer2 的用户名(此处为 root) |
登录成功状态:成功连接后显示版本信息和提示符
# 登录成功的状态如下:
0: jdbc:hive2://master:10000> 3.2.4 退出命令
退出 Beeline 客户端:
使用
!quit或!exit命令可以退出 Beeline 客户端。
清屏:
在命令行界面,可以使用
Ctrl + L快捷键进行清屏。
3.2.5 停止 Hive 服务
查看服务进程:
jps -m
示例输出:
# 可以看到下面的两个RunJar
16819 RunJar # Metastore
28247 RunJar # HiveServer2终止进程:
kill -9 16819 # 终止 Metastore
kill -9 28247 # 终止 HiveServer2
3.2.6 过滤掉启动服务时 WARN的警告日志【可选操作】
1.SLF4J 多重绑定 → 日志类冲突警告,可清理多余 jar。【此教程不处理】
2.DataNucleus jdbc-type null → Hive 元数据映射警告,不影响功能,可忽略。【处理此项警告信息】

解决方法:
编辑 $HIVE_HOME/conf 下 log4j2.properties文件
# 修改下面的日志级别为ERROR,原为WARN
log4j.rootLogger=ERROR, CA保存退出 ,重启Hive的两个服务,即可生效
4、HIVE的基本操作:库、表
1. 说明与命名规范
默认数据库:Hive 有一个默认的数据库
default,如果在执行 HQL 时没有明确指定要使用哪个数据库,则会默认使用default数据库。不区分大小写:Hive 的数据库名和表名都不区分大小写。
命名规则:
名字不能以数字开头。
不能使用 Hive 关键字。
尽量避免使用特殊符号。
2. 创建数据库
-- 语法1:创建数据库(如果不存在);默认存放在 /user/hive/warehouse 目录下
CREATE DATABASE IF NOT EXISTS mydb;
-- 语法2:创建数据库(如果不存在),并指定存放的 HDFS 路径
CREATE DATABASE IF NOT EXISTS mydb \
LOCATION 'hdfs://master:9000/user/hive/warehouse/mydb.db';
# 解释:
# hdfs://master:9000/user/hive/warehouse/mydb.db 指向 HDFS 集群中的一个具体路径,
# 位于 NameNode master 上,端口为 9000,并存储着 Hive 数据库 mydb 的数据。【重点归纳】
Hive 数据库与 HDFS 目录:在创建数据库时,Hive 会在 HDFS 的默认存储路径
/user/hive/warehouse下创建一个与数据库同名的文件夹,用于存储该数据库中所有表的数据文件。每个表的数据将存放在该文件夹下的子目录中。例如,如果你创建了一个名为
mydb的数据库,Hive 会在 HDFS 的/user/hive/warehouse/mydb.db目录中为该数据库创建一个目录,用来存放该数据库的所有表数据。假设在
mydb数据库中创建了一个名为mytable的表,Hive 会在mydb.db目录下生成一个名为mytable的子目录。这个子目录/user/hive/warehouse/mydb.db/mytable将用于存储mytable表的数据文件。数据库和表的元数据信息存储在 Hive 的元数据存储中(如 MySQL),但实际的数据文件始终保存在 HDFS 上的这些目录中。因此,管理和维护这些目录与 Hive 的数据库操作息息相关。
3. 查看所有数据库
SHOW DATABASES;
4. 切换数据库
USE mydb;
5. 查看数据库信息
-- 语法1:查看数据库的基本描述(如数据库的名称和在 HDFS 中的位置)
DESC DATABASE mydb;6. 删除数据库
-- 语法1:删除空数据库
DROP DATABASE databasename;
-- 语法2:强制删除非空数据库及其所有内容
DROP DATABASE databasename CASCADE;【重点归纳】
直接删除 HDFS 中的目录不会清理 Hive 的元数据,而 DROP DATABASE ... CASCADE 是确保数据库及其数据文件彻底删除的正确方式。
删除与重新创建数据库:
在 Hive 中,元数据(如数据库定义和表结构)存储在外部的元数据存储(通常是关系型数据库,例如 MySQL、PostgreSQL 等)中,而实际的数据文件存储在 HDFS 上。
如果你只是手动删除 HDFS 中的数据库目录,Hive 元数据中仍然会保留该数据库的记录。因此,即使 HDFS 上的文件不再存在,Hive 依然认为该数据库存在,导致你无法使用相同的数据库名称重新创建数据库,因为元数据并没有被同步删除。
彻底删除 Hive 数据库:
从元数据存储中删除数据库及其表的记录。
从 HDFS 上删除数据库目录及其关联的所有表的数据文件。
为了从 Hive 的元数据和 HDFS 中完全删除数据库,必须使用 Hive 的
DROP DATABASE 数据库名 CASCADE命令。这个命令的作用是:
使用
CASCADE参数会确保与数据库关联的所有表也被删除,确保数据库及其数据彻底清除,防止保留残余文件或元数据。
5、错误坑点:
5.1 初始化Hive元数据库,出现错误的日志信息
❌ 初始化失败(常见错误)
若出现如下错误,说明 Hive 与 Hadoop 之间存在 Guava 依赖冲突:
Exception in thread "main" java.lang.NoSuchMethodError:
com.google.common.base.Preconditions.checkArgument(ZLjava/lang/String;Ljava/lang/Object;)V
# 翻译
# 主线程中抛出异常:找不到方法 checkArgument(boolean, String, Object),
# 该方法属于 com.google.common.base.Preconditions 类。✅ 报错原因
👉 该错误说明程序调用了
Guava库中的checkArgument方法,但这个方法的参数签名在当前版本的guava.jar中不存在。这是因为:
Hive 自带的是 guava-19.0.jar
Hadoop 依赖的是 guava-27.0-jre.jar
Hive 启动时加载了多个组件(包括 Hadoop 的 lib),出现了 Guava 版本冲突(低版本 API 不兼容)。
✅ 解决方案
查看 Hadoop 中的 Guava 版本
cd /opt/apps/hadoop/share/hadoop/common/lib
ls | grep guava
# 例如:guava-27.0-jre.jar
查看 Hive 中的 Guava 版本
cd /opt/apps/hive/lib
ls | grep guava
# 例如:guava-19.0.jar
替换 Hive 中的 Guava 库
Hive 使用的是 guava-19.0,而 Hadoop 是 guava-27.0,因此需要统一成高版本。
cd /opt/apps/hive/lib
rm -f guava-19.0.jar # 删除旧版本
cp /opt/apps/hadoop/share/hadoop/common/lib/guava-27.0-jre.jar . # 复制新版本
再次初始化 Hive 元数据库:
schematool -initSchema -dbType mysql -verbose如果 guava 版本统一,问题即可解决。
5.2 启动hive客户端,出现错误的日志信息
hive> show tables;
FAILED: SemanticException org.apache.hadoop.hive.ql.metadata.HiveException: java.lang.RuntimeException: Unable to instantiate org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClien
# 问题原因:
hive.site.xml配置了metastore服务,但是没有启动
# 解决方案:
在启动hive客户端前,先启动 hive --service metastore5.3 启动metastore服务时,出现多重的日志信息
hive --service metastore 启动时出现以下日志信息
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/apps/hadoop/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/apps/hive/lib/log4j-slf4j-impl-2.10.0.jar!/org/slf4j/impl/StaticLoggerBinder.class]
# 问题原因:
类路径下包含重复的SLF4J绑定,然后给出了重复的两个全路径类名,可能会导致日志输出异常
hive和hadoop中的SLF4J的jar包重复了
SLF4J:JAVA的日志框架
# 解决方案:
# 建议移除 /usr/local/hive/lib/log4j-slf4j-impl-2.10.0.jar 中的 SLF4J 绑定,因为通常情况下 Hadoop 自带的 slf4j-log4j12-1.7.10.jar 是较为常用的版本,并且这个版本的绑定实现也比较完整。
cd /opt/apps/hive/lib/
mv log4j-slf4j-impl-2.10.0.jar log4j-slf4j-impl-2.10.0.jar.bak5.4 HIVE查看文件日志巧妙方法
1.先关闭hive
# Hive的log默认存放在/tmp/root/hive.log目录下(当前用户名下)
2.再开一个新窗口,输入 tail -f /tmp/root/hive.log # -f 常用于查阅正在改变的日志文件。多敲几个空行,作为此次日志的起始
3.再次打开hive
4.第2个窗口查看日志5.5 beeline客户端运行错误1:
## 方法一:[建议采用这种方法]
# 启动客户端:
1. beeline -u jdbc:hive2://master:10000 -n root
2. 启动客户端后,运行select count(*) from 表名,会启动MR, 出现以下类似报错
# 出现错误:
WARN jdbc.HiveConnection: Failed to connect to master:10000
.......
User: root is not allowed to impersonate root impersonate/模拟/
# 错误类型:
`错误类型:User: AAA is not allowed to impersonate BBB`
- AAA 指的是 hdfs 文件系统的用户
- BBB 是hive 设置的 hiveserver2 配置文件中的登陆用户名
# 分析原因:
`beeline -u jdbc:hive2://master:10000 -n root` 使用的是`root`用户名登录beeline
hive.server2.enable.doAs 是一个 Hive 配置参数,它用于指定是否允许 Hive Server2 使用代理用户的身份进行访问,也就是是否启用 doAs 功能。如果启用了 doAs 功能,那么 Hive Server2 会尝试使用客户端提供的用户名和代理用户名来访问 Hadoop 文件系统和其他 Hadoop 组件,这样就可以实现对 Hadoop 资源的访问控制。
当出现 User: root is not allowed to impersonate root 错误时,通常是因为 Hive Server2 在使用 doAs 功能的情况下,试图使用 root 用户的身份来执行某些操作,但是在 Hadoop 集群中,root 用户是被禁止使用 doAs 功能的。因此,为了解决这个错误,需要在 Hive 配置文件中将 hive.server2.enable.doAs 参数设置为 false,即禁用 doAs 功能。
如果设置为true,HiveServer2会模拟提交用户的身份去执行语句; 如果设置为false,HiveServer2会以启动它的管理员用户来执行语句。
# 解决方法:
# 更改Hive的conf/hive.site.xml,添加以下信息
<!-- 禁用 HiveServer2 的用户模拟功能, Hive查询和操作都将以 HiveServer2 进程的所有者身份运行 -->
<!-- 解决了 `User: root is not allowed to impersonate root` 的错误。 -->
<property>
<name>hive.server2.enable.doAs</name>
<value>false</value>
<description>Enable user impersonation for HiveServer2</description>
</property># 解释:
hive.server2.enable.doAs是Apache Hive的一个配置参数,用于控制是否启用模拟用户(impersonation)。模拟用户允许一个用户代表另一个用户执行操作,这在多个用户需要访问相同资源的情况下非常有用。
当设置该参数为 true 时,Hive Server 2启用模拟用户,这意味着用户可以代表另一个用户执行操作。例如,如果用户A有权限访问某个资源,而用户B没有这些权限,则用户B可以使用模拟用户来以用户A的身份访问该资源。
但是,如果将该参数设置为 false,则禁用模拟用户,用户只能基于其自身的权限访问资源。重启hadoop集群
重新启动Hive的metastore和hiveserver2服务
再次启动beeline,问题解决
## 方法二:[使用方法一,此方法不再使用]
# 启动客户端:
1. beeline -u jdbc:hive2://master:10000 -n root
2. 启动客户端后,运行select count(*) from 表名,会启动MR, 出现以下类似报错
# 出现错误:
WARN jdbc.HiveConnection: Failed to connect to master:10000
.......
User: root is not allowed to impersonate root impersonate/模拟/
# 错误类型:
`错误类型:User: AAA is not allowed to impersonate BBB`
- AAA 指的是 hdfs 文件系统的用户
- BBB 是hive 设置的 hiveserver2 配置文件中的登陆用户名
# 分析原因:
`beeline -u jdbc:hive2://master:10000 -n root` 使用的是`root`用户名登录beeline
此方法是通过hive的thrift服务来实现跨语言访问Hive数据仓库,但是hadoop引入了一个安全伪装机制,使得hadoop不允许上层系统直接将实际用户传递到hadoop层,而是将实际用户传递给一个超级代理,由此代理在hadoop上执行操作,从而避免任意客户端随意操作hadoop。
`任何用户,要提交任务到hadoop上必须配置代理用户
图上的超级代理是“Oozie”,你自己的超级代理是下面设置的proxyuser后面的“xxx”。
解决措施:
允许用 root 用户登录hive
在hadoop的core-site.xml中添加(三台机器都要进行更改添加)
<!-- 下面配置中root是hdfs文件系统的用户名 -->
<!-- 允许 root 用户从任何主机代理任何组的用户,进行各种操作。 -->
<!-- root 用户可以从任何主机代理用户访问hdfs集群-->
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<!-- root 用户可以代理任何组的用户-->
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>重启hadoop集群
重新启动Hive的metastore和hiveserver2服务
再次启动beeline,问题解决
5.6 Hive表字段Comment中文乱码、Hive视图的中文显示为?
问题:默认Hive中创建有中文注释的表时,无论是在Hive CLI还是IDEA中该注释显示都会是乱码。
解决:
# 1.在mysql中运行下面的命令,检查当前数据库的字符集设置;
SHOW VARIABLES LIKE 'character_set%';
# 确保 character_set_database 和 character_set_server 的值为 utf8mb4。
# 2.打开 MySQL 配置文件(例如 /etc/my.cnf ),没有则创建,添加或更改为如下信息
[client]
default-character-set=utf8
[mysqld]
default-storage-engine=INNODB
character-set-server=utf8
collation-server=utf8_general_ci
# 3.在 mysql 修改hive元数据表注释和字段注释的编码为 utf-8
选择元数据库,一般是hive,本机是hivedb
use hivedb
修改表字段注解和表注解
alter table COLUMNS_V2 modify column COMMENT varchar(256) character set utf8;
alter table TABLE_PARAMS modify column PARAM_VALUE varchar(4000) character set utf8;
修改分区字段注解
alter table PARTITION_PARAMS modify column PARAM_VALUE varchar(4000) character set utf8 ;
修改索引注解
alter table PARTITION_KEYS modify column PKEY_COMMENT varchar(4000) character set utf8;
# 4. 查看TBLS 表,其存储 Hive 中所有表的元数据信息,如表名、类型、存储位置等。
show create table TBLS;
# 发现视图有关的字段编码为latin1,修改这两个字段的编码为utf8
ALTER TABLE `TBLS` MODIFY COLUMN `VIEW_EXPANDED_TEXT` mediumtext CHARACTER SET utf8mb4;
ALTER TABLE `TBLS` MODIFY COLUMN `VIEW_ORIGINAL_TEXT` mediumtext CHARACTER SET utf8mb4;
# 5.重启 MySQL 服务以使修改生效
sudo service mysql restart删除旧表,重新建新表,能正常显示中文。
5.7 日志冲突
[root@master ~]# hdfs dfs -ls /user/hive/warehouse/itcast.db
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/opt/apps/hadoop/share/hadoop/common/lib/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/opt/apps/hive/lib/log4j-slf4j-impl-2.10.0.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]错误原因: Hive输入命令时出现日志冲突提示,slf4j在两处找到了jar包。分别是在Hadoop和hive的安装目录。 删除一个就好。
解决方案:
一种是屏蔽日志冲突包,一种删除多余包
把hive下的重命名
把opt/apps/hive/lib/log4j-slf4j-impl-2.10.0.jar重命名为opt/apps/hive/lib/log4j-slf4j-impl-2.10.0.jar.bak
5.8 Hive 3.1.2 版本命令行日志过多问题的解决方案
问题描述:在使用 Hive 3.1.2 的过程中,进入 hive Shell 后执行任意操作时,命令行窗口会持续输出大量日志信息(如 INFO、DEBUG 级别日志),严重影响查询结果的阅读和调试体验。
解决方法:
在 Hive 安装目录的 conf/ 下,新建或编辑文件 log4j.properties,添加以下内容:
log4j.rootLogger=WARN, CA
log4j.appender.CA=org.apache.log4j.ConsoleAppender
log4j.appender.CA.layout=org.apache.log4j.PatternLayout
log4j.appender.CA.layout.ConversionPattern=%-4r [%t] %-5p %c %x - %m%n注意:如果Hive 安装目录的 conf 目录下有hive-log4j2.properties文件,改名为hive-log4j2.properties.bak,不然会与上面日志发生冲突
5.9 关闭Namedata安全模式
有的时候hive的hive2的runjar已经启动,但是就是hiveserver2服务不能正常开启。原因可能是Namedata处于安全模式,需要关闭此模式。
# 正常关闭
hdfs dfsadmin -safemode leave
# 强制关闭
hdfs dfsadmin -safemode forceExit当Namenode处于“安全模式”下,不能进行HDFS上写操作,故需要关闭此模块

# 解决Namenode的安全模式的问题
# 1.查看Namenode的状态
[root@master ~]# hdfs dfsadmin -safemode get
#结果:Safe mode is ON
# 2.关闭Namenode的安全模式
[root@master ~]# hdfs dfsadmin -safemode forceExit
#结果:Safe mode is OFF5.10 Centos7开机之后连不上网ens33 IP 信息丢失
Centos7主机开机之后连不上网,发现网卡没有启动起来
ens33 mtu 1500 qdisc noop state DOWN group default qlen 1000
解决方案:先停止网卡,然后再重启服务,发现网卡启动了
# Centos7开机之后连不上网ens33 IP 信息丢失
首先在VM中进入不能使用连接的主机
用户名:root
口令:123456
# 1.停止 NetworkManager 服务运行
[root@master ~]# systemctl stop NetworkManager
# 2.重启网络服务
[root@master ~]# service network restart
# 3.查看ens33的IP是否出现
[root@master ~]# ip a
四、场景案例:Apache Hive初体验
1.体验1:Hive使用起来和Mysql差不多吗?
1.1 背景
对于初次接触Apache Hive的人来说,最大的疑惑就是:Hive从数据模型看起来和关系型数据库mysql等好像。包括Hive SQL也是一种类SQL语言。那么实际使用起来如何?
1.2 过程
体验步骤:按照mysql的思维,在hive中创建、切换数据库,创建表并执行插入数据操作,最后查询是否插入成功。
-- 列出所有数据库
show databases;
-- 删除数据库
drop database if exists itcast cascade;
-- 创建数据库
create database if not exists itcast;
-- 选择数据库
use itcast;
-- 建表
create table t_student(id int,name varchar(255));
-- 查看表
show tables;
-- 插入一条数据
insert into table t_student values(1,"allen");
-- 查询表数据
select * from t_student;在执行插入数据的时候,发现插入速度极慢,sql执行时间很长,为什么?

最终插入一条数据,历史30秒的时间。

查询表数据,显示数据插入成功

1.3 验证
HDFS Web UI: http://master:9870

首先登陆Hadoop YARN上观察是否有MapReduce任务执行痕迹。
YARN Web UI: http://slave1:8088/

然后登陆Hadoop HDFS浏览文件系统,根据Hive的数据模型,表的数据最终是存储在HDFS和表对应的文件夹下的。
1.4 结论
Hive SQL语法和标准SQL很类似,使得学习成本降低不少。
Hive底层是通过MapReduce执行的数据插入动作,所以速度慢。
如果大数据集这么一条一条插入的话是非常不现实的,成本极高。
Hive应该具有自己特有的数据插入表方式,结构化文件映射成为表。
2.体验2:如何才能将结构化数据映射成为表?
2.1 背景
在Hive中,使用insert+values语句插入数据,底层是通过MapReduce执行的,效率十分低下。此时回到Hive的本质上:可以将结构化的数据文件映射成为一张表,并提供基于表的SQL查询分析。
假如,现在有一份结构化的数据文件,如何才能映射成功呢?在映射成功的过程中需要注意哪些问题?不妨猜想文件的存储路径?字段类型?字段顺序?字段之间的分隔符问题?
2.2 过程
在HDFS根目录下创建一个结构化数据文件user.txt,里面内容如下
1,zhangsan,18,beijing
2,lisi,25,shanghai
3,allen,30,shanghai
4,woon,15,nanjing
5,james,45,hangzhou
6,tony,26,beijing 把user.txt拖动到master节点的/root目录下

在hive中的itcast数据库下创建数据表t_user。注意:字段的类型顺序要和文件中字段保持一致。
-- 创建数据库
create database if not exists itcast;
-- 选择数据库
use itcast;
-- 创建数据表,增加分隔符指定语句
create table t_user(
id int,
name varchar(255),
age int,
city varchar(255))
row format delimited
fields terminated by ',';
-- 解释:
-- ROW FORMAT DELIMITED 指示 Hive 使用分隔符格式来解析表中的数据
-- FIELDS TERMINATED BY ',' 指定了具体的字段分隔符(在此情况下为逗号)。
-- 查看库中有哪些表
show tables;
-- 在master节点上操作,把本地数据上传到Hive在HDFS上的家目录下的数据库itcast.db下的数据表t_user
[root@master ~]# hdfs dfs -put user.txt /user/hive/warehouse/itcast.db/t_user
-- 查看表内容
select * from t_user;2.3 验证

此时再创建一张表,保存分隔符语法,但是故意使得字段类型和文件中不一致。
-- 建表语句 增加分隔符指定语句
create table t_user_2(
id int,
name int,
age varchar(255),
city varchar(255))
row format delimited
fields terminated by ',';
#把user.txt文件从本地文件系统上传到hdfs
hadoop fs -put user.txt /user/hive/warehouse/itcast.db/t_user_2/
-- 执行查询操作
select * from t_user_2;
此时发现,有的列显示null,有的列显示正常。
name字段本身是字符串,但是建表的时候指定int,类型转换不成功;age是数值类型,建表指定字符串类型,可以转换成功。说明hive中具有自带的类型转换功能,但是不一定保证转换成功。
2.4 结论
要想在hive中创建表跟结构化文件映射成功,需要注意以下几个方面问题:
创建表时,字段顺序、字段类型要和文件中保持一致。
如果类型不一致,hive会尝试转换,但是不保证转换成功。不成功显示null。
文件好像要放置在Hive表对应的HDFS目录下,其他路径可以吗?
建表的时候好像要根据文件内容指定分隔符,不指定可以吗?
3.体验3:使用hive进行小数据分析如何?
3.1 背景
因为Hive是基于HDFS进行文件的存储,所以理论上能够支持的数据存储规模很大,天生适合大数据分析。假如Hive中的数据是小数据,再使用Hive开展分析效率如何呢?
3.2 过程
之前我们创建好了一张表t_user,现在通过Hive SQL找出当中年龄大于20岁的有几个。

3.3 验证
--执行查询操作
select count(*) from t_user where age > 20;发现又是通过MapReduce程序执行的数据查询功能。

3.4 结论
Hive底层的确是通过MapReduce执行引擎来处理数据的
执行完一个MapReduce程序需要的时间不短
如果是小数据集,使用hive进行分析将得不偿失,延迟很高
如果是大数据集,使用hive进行分析,底层MapReduce分布式计算,很爽
五、DBeaver连接hive
DBeaver是一个非常好用的数据库管理工具,支持多种不同的数据库类型。
在hive 的安装配置包中,有一个目录:jdbc里面有一个专门提供外部程序连接hive的jar。将这个jar下载后,在使用dbeaver工具建立与hive连接时,配置到驱动路径下就行
1、找到hive服务安装路径下的jdbc目录,并将下面jar包下载。
/opt/apps/hive/jdbc/hive-jdbc-3.1.2-standalone.jar
2、打开dbeaver工具在创建数据库连接中找到Apache Hive
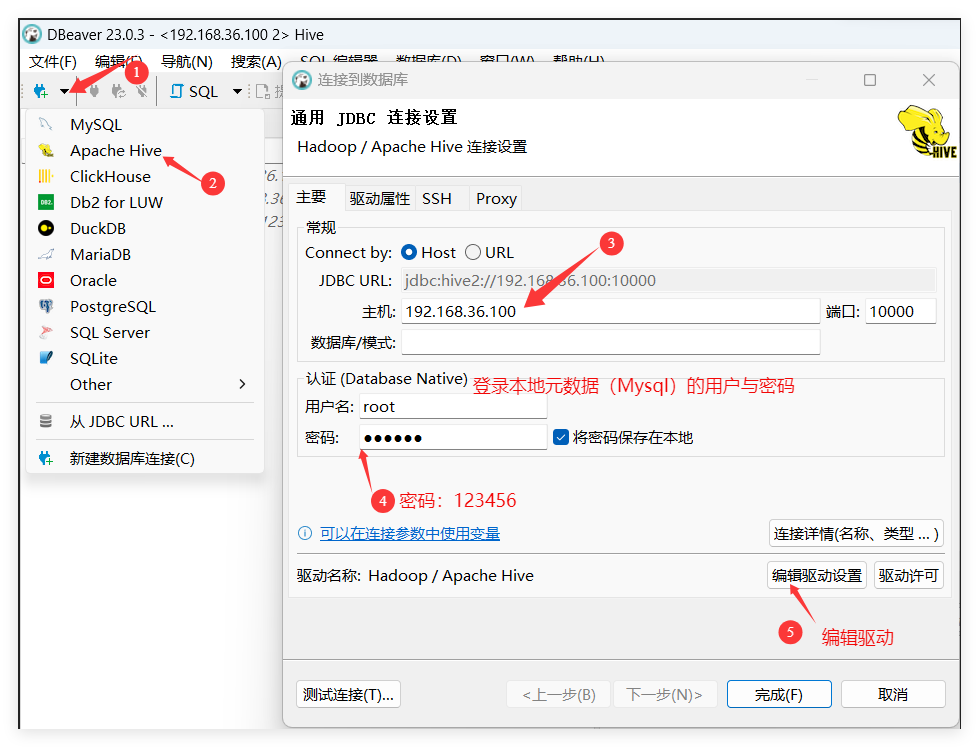
3、在连接设置中设置好服务器地址和登录账号密码信息,点击:编辑驱动设置
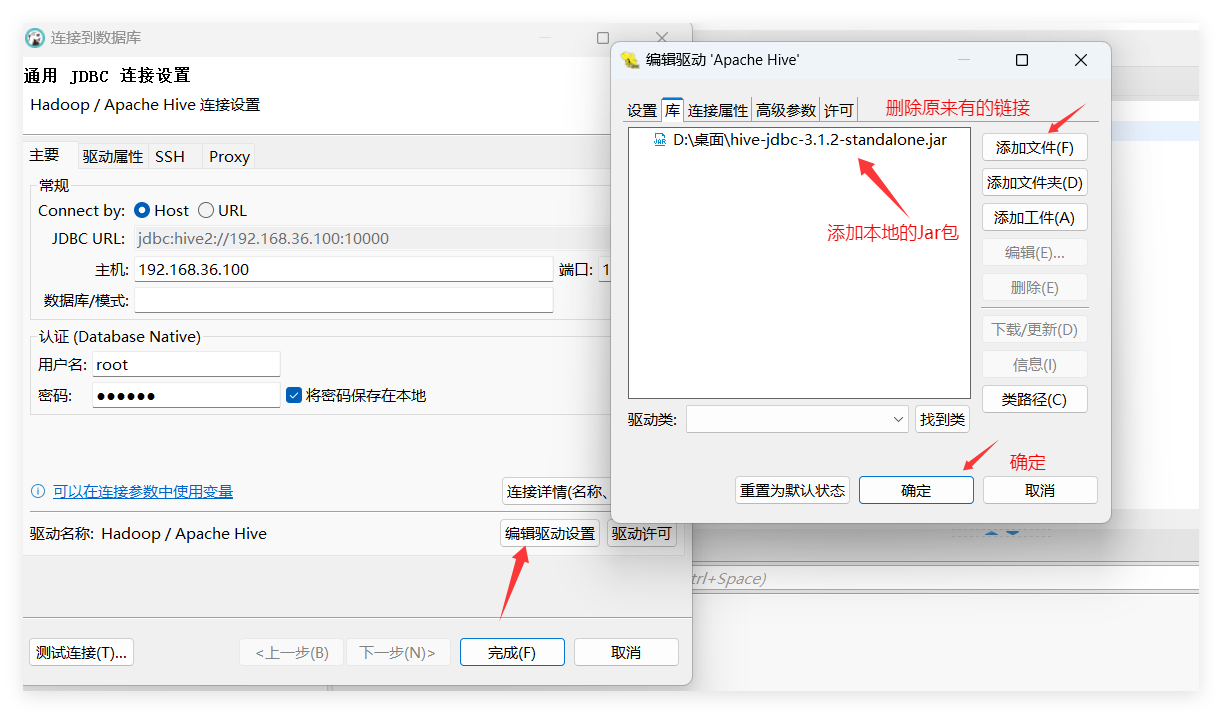
4、测试连接,完成
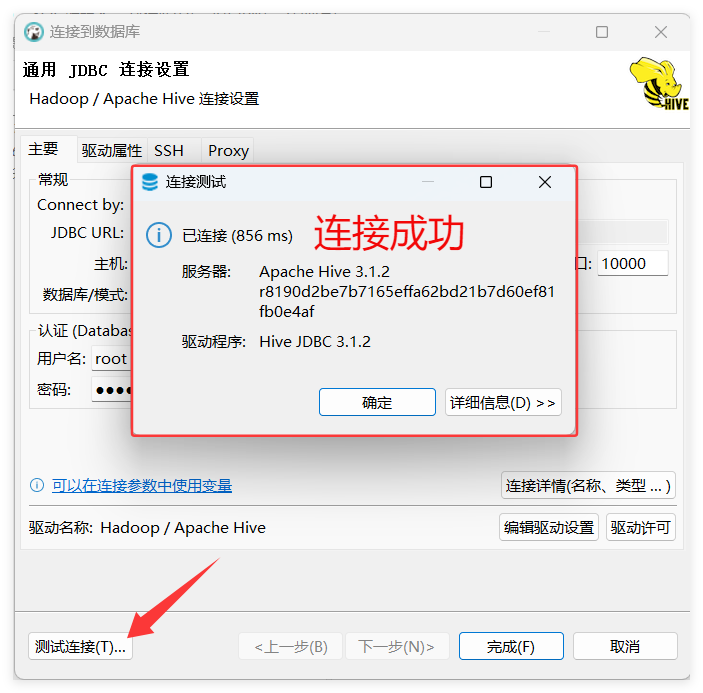
六、实验
启动环境
# 启动Hadoop
start-dfs.sh #在master上启动HDFS
start-yarn.sh #在slave1上启动Yarn
# 启动Hive服务
hive --service metastore & # 后台启动元数据服务
hive --service hiveserver2 & # 后台启动远程访问服务
# 启动 Beeline 客户端
beeline -u jdbc:hive2://master:10000 -n root创建数据库
# 创建一个名为 `my_database` 的数据库:
CREATE DATABASE my_database;使用数据库
# 切换到刚刚创建的数据库:
USE my_database;创建用户表
# 创建一个用户信息表 `t_user`:
CREATE TABLE t_user(
id INT,
name STRING,
age INT,
city STRING
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORED AS TEXTFILE;-- 代码注释
-- 创建一个名为 `t_user` 的表,用于存储用户信息
CREATE TABLE t_user (
id INT, -- 用户的唯一标识,类型为整数
name STRING, -- 用户的姓名,类型为字符串
age INT, -- 用户的年龄,类型为整数
city STRING -- 用户所在的城市,类型为字符串
)
-- 定义表的行格式,表示每一行的数据如何解析
ROW FORMAT DELIMITED
-- 指定字段之间使用逗号 (',') 进行分隔
FIELDS TERMINATED BY ','
-- 指定数据存储格式为文本文件(TextFile)
STORED AS TEXTFILE;插入用户数据
把数据
users_data.csv拖动到master节点的/opt/data/路径下# 在master节点下运行下面的命令,加载本地数据到Hive的表中
hdfs dfs -put /opt/data/users_data.csv /user/hive/warehouse/my_database.db/t_user/创建订单表
# 创建一个订单信息表 `t_order`:
CREATE TABLE t_order(
order_id INT,
user_id INT,
product STRING,
amount DECIMAL(10,2),
order_date DATE
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
STORED AS TEXTFILE;插入订单数据
把数据
orders_data_2023.csv拖动到master节点的/opt/data/路径下# 在master节点下运行下面的命令,加载本地数据到Hive的表中
hdfs dfs -put /opt/data/orders_data_2023.csv \
/user/hive/warehouse/my_database.db/t_order/查询数据
# 8.1 查询所有用户的信息:
SELECT * FROM t_user;# 8.2 查询所有订单的信息:
SELECT * FROM t_order;# 8.3 查询所有用户的姓名和城市
SELECT name, city FROM t_user;# 8.4 查询年龄大于30岁的用户
SELECT * FROM t_user WHERE age > 30;# 8.5 查询用户数量(总数)
SELECT COUNT(*) AS total_users FROM t_user;# 8.6 查询每个城市的用户数量
SELECT city, COUNT(*) AS user_count
FROM t_user
GROUP BY city;# 8.7 查询订单金额大于5000元的订单
SELECT * FROM t_order WHERE amount > 5000;# 8.8 查询每个用户的订单数量
SELECT u.name, COUNT(o.order_id) AS order_count
FROM t_user u
LEFT JOIN t_order o ON u.id = o.user_id
GROUP BY u.name;# 8.9 查询所有订单的总金额
SELECT SUM(amount) AS total_amount FROM t_order;# 8.10 查询每个用户的总订单金额(包括用户没有订单的情况)
SELECT u.name, COALESCE(SUM(o.amount), 0) AS total_amount
FROM t_user u
LEFT JOIN t_order o ON u.id = o.user_id
GROUP BY u.name;# 8.11查询最近一次订单的日期
SELECT MAX(order_date) AS latest_order_date FROM t_order;# 8.12 查询用户年龄的平均值
SELECT AVG(age) AS average_age FROM t_user;退出 Beeline
输入
!quit或!exit以退出 Beeline。