一、前言
怎么学习大数据技术?
—— 多练习!多练习!再多练习! 理论只是基础,真正的能力来自不断的动手实践。
1.1 必备的基础知识
(1)基础能力
英语:掌握计算机专业英语(Java、Python、Web、MySQL 等领域常用术语)。
数学:为后续专升本、机器学习、算法、数学建模打下基础。
交叉学科能力:计算机 + 网络 + 数学 + 统计学 的综合能力。
(2)计算机专业知识
编程语言
Java:Hadoop 生态系统的核心语言(MapReduce、HDFS、YARN 等底层框架几乎都用 Java 编写)。
Python:数据分析、数据可视化、机器学习领域的热门语言。
Scala:Spark 程序开发的主流语言(与 Java 同等重要)。
前端基础:
HTML + CSS + JavaScript(用于大数据可视化、交互页面开发)。数据库:
MySQL(掌握 SQL 语句和数据查询分析能力)。计算机网络:理解基本原理,有助于集群部署与运维。
操作系统:
Linux(大数据集群的主流运行环境;熟练使用常用命令与 Shell 脚本)。
1.2 学习难度
环境要求高:需要硬件环境、软件环境、数据环境三者配合。
学习成本高:涉及的知识面广、技术迭代快,需要持续投入时间和精力。
1.3 一分钟互联网数据量
以下是互联网在 1 分钟 内产生的数据量(部分平台):
| 平台/应用 | 1分钟内产生的数据/交易量 |
|---|---|
| 微信 | 发布 46.52 万张 图片,发起 22.91 万次 视频通话,54.16 万人 进入朋友圈 |
| 百度 | 416.6 万次 搜索,6.94 万次 语音播报 |
| 美团 | 3.06 万单 订单 |
| 淘宝 | 销售额 658.8 万元 |
| 天猫 | 销售额 767.59 万元 |
| 滴滴 | 2.84 万单 出行订单 |
| B站 | 83.3 万次 视频播放 |
| 京东 | 销售额 496.57 万元 |
| 抖音 | 1.67 亿条 视频播放 |
二、大数据的概念
数据太大、太快、太复杂,传统方法搞不定,就需要用 新技术 来处理。
2.1 主要解决的问题
海量数据存储
海量数据分析计算
“海量”的单位认知:
1 Byte = 8 bit 【即 1 个字节由 8 个二进制位组成,可表示 2^8 = 256 种状态】
1 KB = 1024 Byte
1 MB = 1024 KB
1 GB = 1024 MB
1 TB = 1024 GB
1 PB = 1024 TB
1 EB = 1024 PB
1 ZB = 1024 EB ...
2.2 大数据的五大特征(5V)
| 特征 | 含义 | 例子/数据冲击 |
|---|---|---|
| Volume(大量) | 数据规模巨大 | 人类所有印刷材料 ≈ 200PB;全人类说过的话 ≈ 5EB;大型企业数据接近 EB 级 |
| Velocity(高速) | 数据产生与处理速度快 | 2025 年全球数据量预计 163ZB(可存 32.6 万亿部高清电影,看完需 89 亿年) |
| Variety(多样) | 数据类型多样化 | 结构化(数据库、表格)、非结构化(视频、音频、图片、日志、位置) |
| Value(低价值密度) | 有用数据占比低 | 社交媒体海量内容中,有商业价值的仅占少部分,需要“提纯” |
| Veracity(真实性) | 数据准确性、可信度 | 数据源质量、采集方式、清洗过程都影响真实性 |
2.3 大数据的应用场景
短视频推荐 抖音基于用户行为(观看、点赞、评论)进行个性化视频推荐。 推荐算法流程图 : “
用户行为数据 → 特征提取 → 算法模型 → 视频推荐”。电商广告推荐 淘宝、京东通过大数据精准分析用户兴趣,推荐可能购买的商品。 大数据推荐系统架构:“
用户画像 + 商品画像 → 匹配 → 推荐列表”零售经典案例 纸尿布 + 啤酒:超市发现买尿布的多是父亲,顺路买啤酒概率高 → 促销捆绑提高销量。
物流仓储优化 京东物流利用大数据预测订单,优化配送路线,实现“上午下单,下午送达”。
保险定价与营销 通过风险预测与用户画像,精准制定保险费率和营销方案。
金融风控 多维度分析用户行为,识别优质客户,防范欺诈风险。
房地产决策 利用市场数据,精准选址、设计、定价与营销。
智慧城市与智能家居(AI + 5G + IoT)
智慧交通:采集交通传感器、摄像头数据 → 实时调整红绿灯,预测拥堵,优化公交调度。
智能家居:分析用户生活习惯 → 自动调节空调、灯光、安全系统,并结合虚拟现实提升体验。
2.4 大数据发展前景
国家战略推动
党的十九大提出 “推动互联网、大数据、人工智能和实体经济深度融合”,大数据已上升到国家发展战略层面。
2020 年中央推出 34 万亿“新基建”投资计划,包括 5G 基站、工业互联网、人工智能平台、数据中心等,这些都需要大数据技术支撑。
政策新风口——AI Plus
2024 年,全国人大会议提出 “AI Plus”政策,目标是用人工智能和大数据平台推动医疗、教育、制造等传统行业的数字化升级。
类似 2015 年的“互联网+”,但覆盖面更广、数据量更大、技术门槛更高。
行业应用全面落地
医疗:国家卫健委推动全国健康医疗大数据平台建设,实现跨省就诊信息互通。
金融:大数据风控减少 50% 欺诈贷款率,信用评估速度提升至秒级。
物流:京东、顺丰的智能调度系统让“当日达”成为常态,配送路径优化可节省 10%~15% 成本。
人才稀缺 + 薪资优势明显
开设时间短:大数据专业 2017 年才在全国 25 所高校首批开设;相比 Java、前端十多年的人才积累,大数据人才基数极小。
岗位缺口大:根据智联招聘 & BOSS 直聘数据,2024 年大数据相关岗位需求同比增长 42%,平均招聘薪资 15K-30K,而同等学历的 Java 初级开发薪资多在 8K-15K。
复合型人才紧缺:既懂数据开发,又会算法建模和业务分析的全栈型数据人才,更是“年薪 50 万“
三、Hadoop 生态体系
3.1 Hadoop 基础介绍
Hadoop 是一个分布式系统基础框架,主要解决 海量数据的存储 和 海量数据的计算 问题。
📌 电商行业应用案例
背景与挑战
大型电商平台(如阿里巴巴、京东)每天有数百万用户浏览、搜索、购买。
用户行为数据(浏览、搜索、下单等)庞大且复杂,传统数据库处理速度变慢,实时推荐受影响。
解决方案:引入 Hadoop
HDFS 分布式存储:将数据切分为数据块,分布在多台服务器,提高访问速度和容错性。
MapReduce 并行计算:将计算任务拆分后并行执行,快速生成个性化推荐结果。
结果与优势
处理速度大幅提升,解决了性能瓶颈。
优化用户体验,实现了实时推荐和精准营销。
3.2 Hadoop 的优势(4 高)
高可靠性:多副本存储,单机宕机不会导致数据丢失。
高扩展性:可轻松增加节点扩容。
高效率:任务并行执行,加快处理速度。
高容错性:任务失败可自动重新调度执行。
3.3 Hadoop 的核心组件
HDFS(Hadoop Distributed File System)——分布式存储
将数据分块存储在不同节点,提供高吞吐和容错。
MapReduce——分布式计算
将任务分解成 Map 和 Reduce 两个阶段并行计算。
YARN(Yet Another Resource Negotiator)——资源调度
管理与调度集群资源,提高资源利用率。
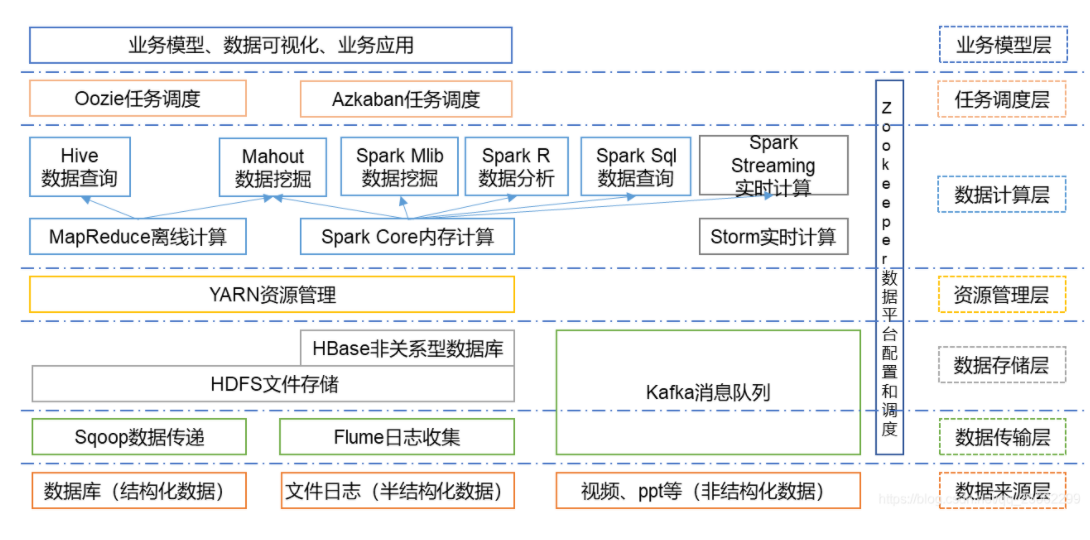
四、大数据Hadoop生态圈-组件介绍
Hadoop的核心组件生态圈结构如图所示:

五、大数据与云计算、物联网的关系
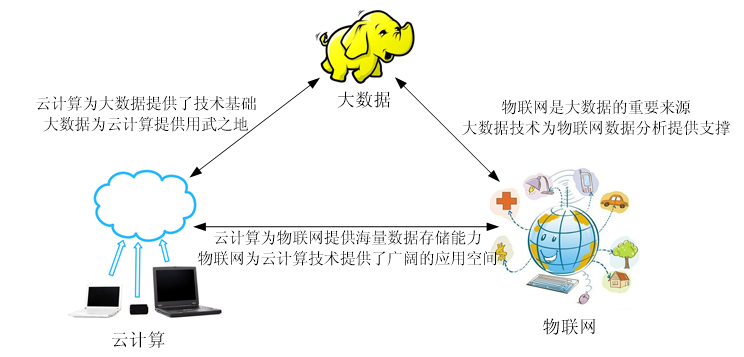
云计算就是把计算机的资源(比如电脑、硬盘、软件)放到“云端”,让我们通过网络随时使用。
一个在中国广泛应用的云计算例子是阿里云(Alibaba Cloud)。阿里云是中国最大的云服务提供商,为各类企业和组织提供全面的云计算服务,包括计算、存储、数据库、网络、安全等。
阿里云提供的云服务主要依托于大量分布在全球各地的数据中心,这些数据中心内部有成千上万的物理服务器。这些服务器通过虚拟化技术,可以运行多个虚拟机,每个虚拟机可以被看作是一台“云上的电脑”。这些虚拟机可以被用来处理计算任务、存储数据、运行应用等。
公司不再自己买服务器,而是在阿里云上租用计算机资源
学校可以在云平台上部署系统,比如学生成绩管理系统
视频网站可以把海量视频存在云上,按需播放
阿里云的应用场景
电商平台支持:天猫和淘宝
背景: 天猫和淘宝是阿里巴巴旗下的两大电商平台,拥有海量的用户和商品,尤其是在“双十一”购物节期间,网站的流量激增。
云计算应用: 阿里云为天猫和淘宝提供了强大的计算和存储能力,支持在高峰期快速扩展资源,以应对数以亿计的交易和访问请求。例如,在“双十一”购物节当天,阿里云能够动态调配计算资源,确保平台在超高流量下依然稳定运行。这种灵活的扩展能力是传统数据中心难以实现的。

六、算法
算法(Algorithm)就是:
解决问题的一套“操作步骤”或“处理规则”,就像做菜时的食谱,或者打游戏时的通关攻略。
示例一:导航算法 = “帮你找路的算法”
场景: 打开手机地图,输入出发地和目的地
发生了什么? 地图应用会使用导航算法,快速帮你找出一条“最快/最短/最顺”的路线
考虑因素: 距离、红绿灯、交通拥堵、修路情况
就像什么? 👉 就像看“出锅步骤”的食谱那样:一步一步引导你走对路线
背后的算法思想: 最短路径算法
示例二:搜索算法 = “帮你找信息的算法”
场景: 在百度或谷歌上搜索“什么是大数据?”
发生了什么? 搜索引擎会使用搜索算法,在几亿个网页中找到最相关的前几条结果展示给你
考虑因素: 关键词是否匹配、网页有没有人常点、网站是不是可靠
就像什么? 👉 就像在书堆里找一本书,算法就是那个熟练的图书管理员,能马上帮你找出来
背后的算法思想: 关键字匹配 + 排序 + 推荐算法
七、机器学习
通俗定义:
机器学习就是“教计算机自己学会做事情”,让它用大量数据自己找规律、总结经验。而不是一步步告诉它怎么做。
和传统编程有什么区别?
| 比较 | 传统编程 | 机器学习 |
|---|---|---|
| 谁来定规则? | 程序员写规则 | 计算机从数据中自动“学”规则 |
| 怎么解决问题? | 明确写出每一步逻辑 | 提供数据,让它自己找出规律 |
| 适合场景 | 逻辑清晰、步骤固定的任务 | 复杂、多变、难以写出固定规则的任务 |
举个例子:识别猫和狗
| 步骤 | 传统编程 | 机器学习 |
|---|---|---|
| 第一步 | 人工写判断条件:长耳朵=狗、尖耳朵=猫… | 给电脑大量标注好的猫狗图片 |
| 第二步 | 每张图都用规则检查 | 电脑分析图片,总结出猫狗的特征 |
| 第三步 | 识别效果有限 | 新图片来了,它能根据经验猜猫还是狗 |
🎯 就像你没告诉它“猫一定尖耳朵”,它看了成千上万张猫狗照片后,自然就“悟”出了区分方法。
常见应用场景
| 场景 | 说明 | 举例 |
|---|---|---|
| 📷 图像识别 | 识别照片中的人或物 | 人脸解锁、安检识别包里有刀具 |
| 🎤 语音识别 | 把语音转成文字 | 语音输入、小爱同学 |
| 📚 自然语言处理 | 让电脑“懂”人类的语言 | 智能翻译、智能客服 |
| 🎵 推荐系统 | 根据用户喜好推荐内容 | 抖音推视频、淘宝推商品、网易推音乐 |
总结一句话:
机器学习就是让计算机“靠数据学经验”,在没有明确规则的情况下,自己找出答案。
八、三年学习路线图
第一年:计算机基础、
Java/Python编程、数据库、Linux命令第二年:
Hadoop/Spark/Flink/Hive等框架、数据分析与可视化、项目实战第三年:实习、毕业设计、专升本/证书、求职
就业方向
数据开发工程师(Java + 大数据框架)
要求:Java/Scala 基础、大数据框架(Hadoop/Spark)、SQL 熟练、一定编程功底。
数据分析师(Python + 可视化 + 商业分析)
要求:Python/Excel、SQL、数据可视化(Tableau/Power BI/ECharts)、统计分析。
大数据运维工程师(Linux + 集群部署 + 运维工具)
要求:Linux 熟练、集群部署(Hadoop、Hive、Spark)、脚本(Shell/Python)、监控工具。
AI研发助理(Python + 数据预处理 + 基础AI模型)
要求:Python、数据预处理、基础机器学习模型、一定的数学/算法背景
九、继续深造
常见本科衔接专业
| 本科专业方向 | 主要学习内容 | 对应就业领域 |
|---|---|---|
| 计算机科学与技术 | 程序设计、数据结构、操作系统、计算机网络、数据库、人工智能 | 软件开发工程师、系统架构师、数据库管理员 |
| 数据科学与大数据技术 | 数据采集与清洗、数据仓库、数据挖掘、机器学习、可视化分析 | 数据分析师、大数据开发工程师、数据产品经理 |
| 软件工程 | 软件需求分析、软件设计与测试、项目管理、版本控制 | 软件项目经理、测试工程师、全栈开发工程师 |
| 网络工程 | 网络构建与管理、信息安全、云计算网络架构 | 网络管理员、运维工程师、安全工程师 |
| 云计算与技术应用 | 虚拟化、分布式计算、云平台架构、云安全 | 云平台运维工程师、云解决方案架构师 |
| 人工智能 | 深度学习、自然语言处理、计算机视觉、智能机器人 |